
Wharf on a good day
In the earlier post on setting up Apache Nifi and Nifi Registry, two Nifi and Registry deployments set up and integrated with each other. This post will focus on automating the migrations between the two environments. Just to refresh, the following diagram shows what we are trying to achieve.
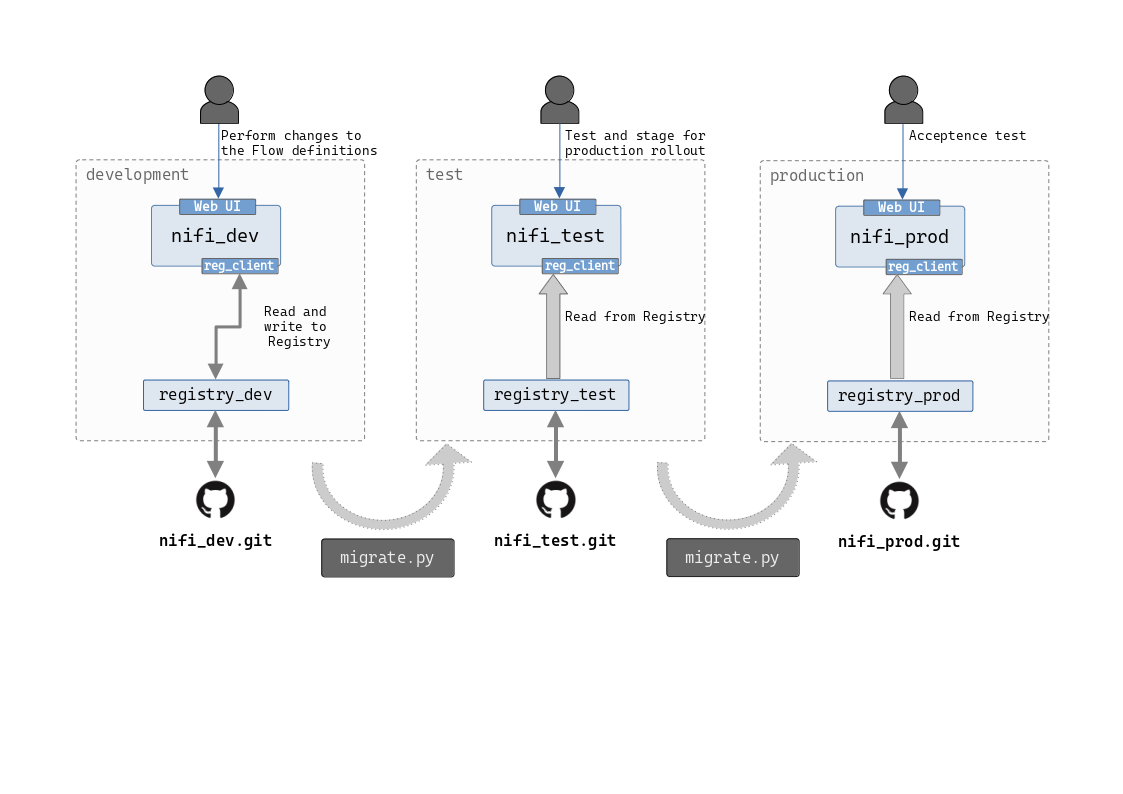
Though this shows three environments, we have only taken the
dev->teststep into consideration in the current and the previous posts. This is because once you automate the series of steps, it’s just a matter of pointing the script to the next step.
Introduction
Both Nifi and the Nifi Registry expose RESTful APIs that can be communicated with through HTTP. However, it’s far easier to work with an API when a good SDK is available. In Nifi’s case, this is NipyAPI. NipyAPI SDK has built-in methods to work with both of the products and is has good documentation that makes the whole exercise a pleasant experience.
In terms of what we want automated, the series of actions we want to focus on are the following.
- Export a set of Process Groups from
devenvironment - Import the Process Groups back to the
testenvironment
They look pretty simple, however there are more considerations in each of these steps.
Implementation
Exporting Process Groups
Connecting to the dev environment
Before we do anything, we need to point the SDK to the dev environment. We do this by using the util.set_endpoint() function.
import nipyapi
#...
#...
# just to keep the logs simple
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# disable TLS check, do at your own risk
nipyapi.config.nifi_config.verify_ssl = False
nipyapi.config.registry_config.verify_ssl = False
# connect to Nifi
nipyapi.utils.set_endpoint("https://localhost:8443/nifi-api")
# wait for connection to be set up
connected = nipyapi.utils.wait_to_complete(
test_function=nipyapi.utils.is_endpoint_up,
endpoint_url="https://localhost:8443/nifi",
nipyapi_delay=nipyapi.config.long_retry_delay,
nipyapi_max_wait=nipyapi.config.short_max_wait
)
# connect to Nifi Registry
nipyapi.utils.set_endpoint("http://localhost:18080/nifi-registry-api")
connected = nipyapi.utils.wait_to_complete(
test_function=nipyapi.utils.is_endpoint_up,
endpoint_url="http://localhost:18080/nifi-registry",
nipyapi_delay=nipyapi.config.long_retry_delay,
nipyapi_max_wait=nipyapi.config.short_max_wait
)
The method util.wait_to_complete() is an interesting one. As you can see, it allows a blocking operation that waits for a given endpoint to be up and available, so technically, the script can start execution before the Nifi and Registry instances are up and ready to receive requests.
Note that the APIs for each of the components are available at the
-apisuffix application, not at the Web application.
Which ones?
We ended the previous post by committing the sample Process Group RandomEvents to version control. However, in a real world scenario there would be multiple, tens of Process Groups in Nifi to be managed. While you can list all the top level Process Groups on the Canvas (the Canvas is the Nifi visual editor UI presented to the user when visiting the Web Console), you may not necessarily want to do that, especially on a dev environment, where different Data Engineers would be working on Process Groups at different states.
A better way to do this is to define a list of Process Groups to be migrated. The script can then lookup the presence of each of the names and export them separately, rather than collecting all the Process Groups across the Canvas.
This can be improved (or depending on your view, made complex) by adding another dimension to the Process Group name input. You can also make it so that the version that should exported for each Process Group is also defined in the input. This would be useful, when it’s required to allow development to progress without waiting on delivery to happen at the same pace. Data Engineers could implement certain changes, commit to the Registry, and continue implementing breaking changes, and when the time to roll out the earlier changes to test comes, the older version can be specified for each Process Group so that the script would only export those versions, and not the latest.
Staging for migration
When exporting, the script will do so from the Registry, not from Nifi. These are two different components, two different binaries, and two different APIs. Because of this, when you request exports from the Registry, you will get the latest version for the specified Flow (or a specified version).
However, if the specific Process Group is not committed to version control, the Registry will not know about it. So it makes sense, from automation perspective, to do a check that the Process Group is committed to version control on the Canvas.
Furthermore, there could be uncommitted changes on the Nifi Canvas, that may have been missed from being added to version control. We can check this using the Nifi API, just to make sure that we are not unintentionally leaving wanted changes behind.
With these in mind, let’s start writing the export logic.
from nypiapi import versioning
#...
#...
# define the list of Process Groups
process_groups = [ "RandomEvents" ]
# store exported flows
exported_flows = {}
ExportedFlow = namedtuple("ExportedFlow", ["name", "bucket_name", "definition"])
for pgn in process_groups:
# make sure there's a Process Group on the Canvas
pg = nipyapi.canvas.get_process_group(pgn, greedy=False)
if pg is None:
print(F"process group {pgn} was not found in the Nifi Canvas")
exit(1)
# make sure the process group is in the Registry
if pg.component.version_control_information is None:
print(F"process group {pgn} is not added to version control")
exit(1)
# make sure there are no uncommitted changes on the Canvas
diff = nipyapi.nifi.apis.process_groups_api.ProcessGroupsApi().get_local_modifications(pg.id)
diffn = len(diff.component_differences)
if diffn > 0:
print(F"there are uncommitted changes in the process group {pgn}")
exit(1)
# since we are here, we found no issue with this Process Group
# let's export it
bucket_id = pg.component.version_control_information.bucket_id
bucket_name = pg.component.version_control_information.bucket_name
flow_id = pg.component.version_control_information.flow_id
# export the latest version from the Registry
flow_json = versioning.export_flow_version(bucket_id, flow_id, version=None)
exported_flows[pgn] = ExportedFlow(pgn, bucket_name, flow_json)
There are few things to elaborate on in this part of the script.
- Notice that we are talking to
canvas.*functions to understand the Canvas status. With the response we get from the Canvas, we can build the data we need for the subsequent API calls. - We then talk to
nifi.*functions, that give us more information about the specific Process Group. - To get an export of the Process Group, we talk to the
versioning.*functions in NipyAPI, which covers the Registry API. - We use a
namedtupleto store the exported Process Group definition. In a later stage, we’ll use the information in the Named Tuple to import the Process Group with correct information. This includes the Registry Bucket name. If you recall from the last post, we are going to use the same Bucket name in the other environments, to keep things simple.
Importing back to test environment
Connecting to the test environment
Before we perform any API calls, we need to switch the connection to the test environment.
# connect to Nifi
nipyapi.utils.set_endpoint("https://localhost:8444/nifi-api")
# wait for connection to be set up
connected = nipyapi.utils.wait_to_complete(
test_function=nipyapi.utils.is_endpoint_up,
endpoint_url="https://localhost:8444/nifi",
nipyapi_delay=nipyapi.config.long_retry_delay,
nipyapi_max_wait=nipyapi.config.short_max_wait
)
# connect to Nifi Registry
nipyapi.utils.set_endpoint("http://localhost:28080/nifi-registry-api")
connected = nipyapi.utils.wait_to_complete(
test_function=nipyapi.utils.is_endpoint_up,
endpoint_url="http://localhost:28080/nifi-registry",
nipyapi_delay=nipyapi.config.long_retry_delay,
nipyapi_max_wait=nipyapi.config.short_max_wait
)
Registry Bucket
As mentioned before, the Registry Bucket we are going to use across environments is the same. Therefore, in the test environment, we can perform a check to see if the Registry Bucket exists, and create if not.
# check if the Bucket already exists
bucket = versioning.get_registry_bucket(bucket_name)
if bucket is None:
bucket = versioning.create_registry_bucket(bucket_name)
Extra checks
We need to consider several scenarios in the case of the test environment.
- There could be a Process Group with the same name (or essentially the same Process Group) on the
testCanvas, but not in the Registry Bucket. This could be because of various reasons, manual edits, user mistakes, or infrastructure failures. - The Process Group could be in the Registry Bucket, and in the Nifi Canvas, but there could be changes in the Canvas, that are not committed to version control. Ideally, a
testorproductionenvironment should not have local changes, as any change should properly propagate along the path to production. However, a tester could do some tweaking to see which changes would solve a specific bug, or there could be a business requirement that forces local changes to be done on the environments other thandev. In any case, the APIs can’t be used to import Process Groups with conflicting names, where there are uncommitted changes. These can be automatically cleaned, however, it’s always advisable to keep this cleaning as a manual task, since vital information could also be lost during such a cleaning.
If all these checks pass, we can proceed with importing the Process Groups on to Canvas.
for flow_name, exported_flow in exported_flows.items():
bucket = versioning.get_registry_bucket(exported_flow.bucket_name)
if bucket is None:
bucket = versioning.create_registry_bucket(bucket_name)
pg = nipyapi.canvas.get_process_group(flow_name, greedy=False)
if pg is not None:
print(F"process group exists on Canvas, but not in Registry: {flow_name}")
exit(1)
else:
bflow = versioning.get_flow_in_bucket(bucket.identifier, flow_name)
pg = nipyapi.canvas.get_process_group(flow_name, greedy=False)
if bflow is None and pg is not None:
print(F"process group exists on Canvas, but not in Registry: {flow_name}")
exit(1)
diff = nipyapi.nifi.apis.process_groups_api.ProcessGroupsApi().get_local_modifications(pg.id)
diffn = len(diff.component_differences)
if bflow is not None and pg is not None and diffn > 0:
print(F"there are uncommitted changes in the process group {pgn}")
exit(1)
Parameter Contexts
Well, not exactly. There is an additional step we have to do before actually performing the API call to import Process Groups.
A Parameter Context in Nifi is basically a set of key value pairs that can be assigned to a Process Group (top level or inner ones). This is a concept that can be used to avoid hard coding environment specific values such as URLs, credentials, parallelization counts, and similar things. By using a Parameter Context, you are basically decoupling the business logic from the actual values.
For an example, if there’s a WebSocket service that a certain Processor connects to, the URL to connect would be different in dev (and possibly test) environment than the one in the production environment. In this case, hard coding the URL in the Processor properties would make it hard to smoothly transition a change through the path to production. In this case, a Parameter Context can be defined (say devparams) in dev and the URL can be defined as a value with key wssurl. In the ConnectWebSocket Processor, this value can be referred to as {#wssurl} and Nifi will assign the value during runtime from the Parameter Context.
This however presents a problem for our script. When we used versioning.export_flow_version() function to export the Process Group, the associated Parameter Context was also exported. This can’t be directly imported into the test environment, since Nifi does not allow importing an attached Parameter Context. In the versions that I deployed the more specific version of this script, Nifi would just put out an NPE without a proper explanation, however the cause is clear.
The solution is to sanitize the Flow definitions before we perform the import API call. We have to remove the references to the Parameter Contexts from the top level Process Group as well as any internal Process Groups (though our sample Process Group doesn’t have any internal Process Groups or even a Parameter Context)
Create or Update?
After sanitization, we are finally ready to perform an import. After an import, we have to update Nifi Canvas so that the latest version imported into the Registry is reflected on the Canvas. However the way to do this differs if we are updating an existing flow. Therefore, we have to first check if we need to perform an update API call instead of a create one, by checking if the Registry Bucket already has a Flow with the same name (a minor detail to note, if the Flow existed on the Canvas and not on the Registry, we’d have errored out during the checks above).
With these considerations in mind, we can start writing the rest of the logic.
def sanitize_pg(pg_def):
"""
sanitize the processGroup section from parameterContext references, does a
recursive cleanup of the processGroups if multiple levels are found.
"""
if "parameterContextName" in pg_def:
pg_def.pop("parameterContextName")
if "processGroups" not in pg_def or len(pg_def["processGroups"]) == 0:
return pg_def
for pg in pg_def["processGroups"]:
sanitize_pg(pg)
#...
#...
# get the registry client for the test environment, we need this to import
# process groups
reg_clients = versioning.list_registry_clients()
test_reg_client = None
# just getting the first registry client we find, assuming we only have one
for reg_client in reg_clients.registries:
test_reg_client = reg_client.component
break
# read the Canvas root element ID to attach Process Groups
root_pg = nipyapi.canvas.get_root_pg_id()
for flow_name, exported_flow in exported_flows.items():
flow = json.loads(exported_flow.definition)
# get the bucket details
bucket = versioning.get_registry_bucket(exported_flow.bucket_name)
# remove from top level Process Group
if "parameterContexts" in flow:
param_ctx = flow["parameterContexts"]
flow["parameterContexts"] = {}
if "parameterContextName" in flow["flowContents"]:
flow["flowContents"].pop("parameterContextName")
# additionally, sanitize inner Process Groups
for pg in flow["flowContents"]["processGroups"]:
sanitize_pg(pg)
sanitized_flow_def = json.dumps(flow)
# check if the process group exists in the bucket
existing_flow = versioning.get_flow_in_bucket(bucket.identifier, flow_name)
if existing flow is None:
# import anew into the Registry
vflow = versioning.import_flow_version(
bucket.identifier,
encoded_flow=sanitized_flow_def,
flow_name=flow_name)
time.sleep(5)
# deploy anew into the Canvas
versioning.deploy_flow_version(
parent_id=root_pg,
location=(0, 0),
bucket_id=bucket.identifier,
flow_id=vflow.flow.identifier,
reg_client_id=test_reg_client.id,
)
else:
# update Flow in Registry in place
vflow = versioning.import_flow_version(
bucket_id=bucket.identifier,
encoded_flow=sanitized_flow_def,
flow_id=existing_flow.identifier)
time.sleep(5)
# check if the Canvas already has the Process Group
pg = nipyapi.canvas.get_process_group(flow_name, greedy=False)
if pg is None:
# deploy anew into the Canvas
versioning.deploy_flow_version(
parent_id=root_pg,
location=(0, 0),
bucket_id=bucket.identifier,
flow_id=vflow.flow.identifier,
reg_client_id=test_reg_client.id,
)
else:
# update Canvas in place
versioning.update_flow_ver(process_group=pg)
Things to note in this part of the script are,
sanitize_pg()function, which is a recursive function to clean any Process Group found at any level to strip Parameter Context information.- Reading the Registry Client information, which is later used as a reference for the Process Group import function
- Use of the
versioning.import_flow_version()function when creating vs updating. Creation of a Flow in the Registry does not require a Flow identifier, since there is none to refer to in the Registry. In contrast, updating requires you to specify the Flow identifier. - The function to deploy a Flow from the Registry to the Canvas is in the
versioningpackage. This requires the root Process Group to refer to, since a Process Group can also attached to another Process Group. In our case, we are going to import the Process Group to the top level Nifi Canvas.
Conclusion
End results
The final result of this script being executed can be seen in the following screenshot. dev is on the left side, and test is on the right.
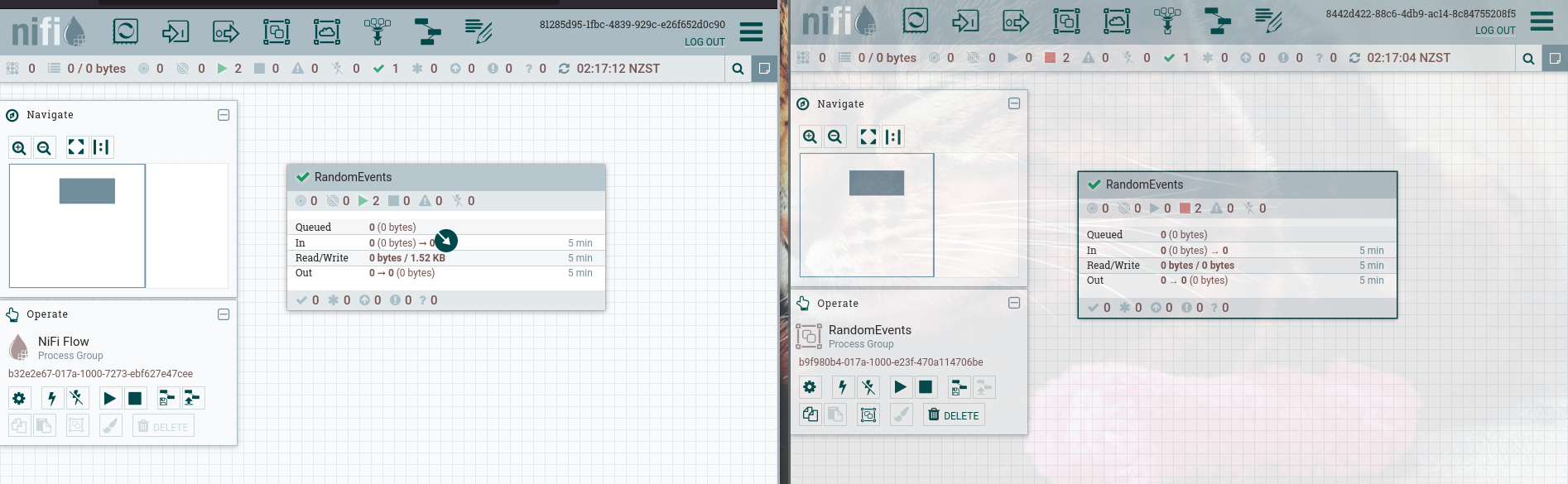
If I wanted to propagate a change, I can do so by committing the changes again to the Registry in dev and running this script again.
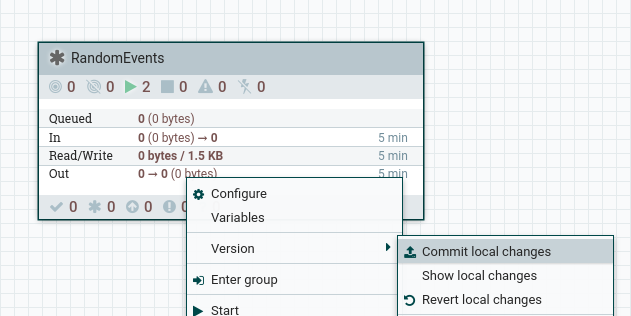
By looking at the versions in the test version I can verify the version I’m at by referring to the commit message (another reason why you should use meaningful commit messages).
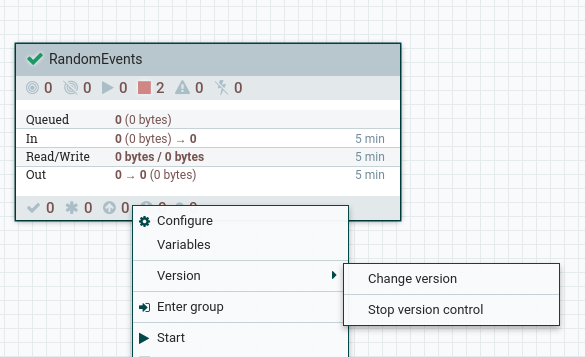
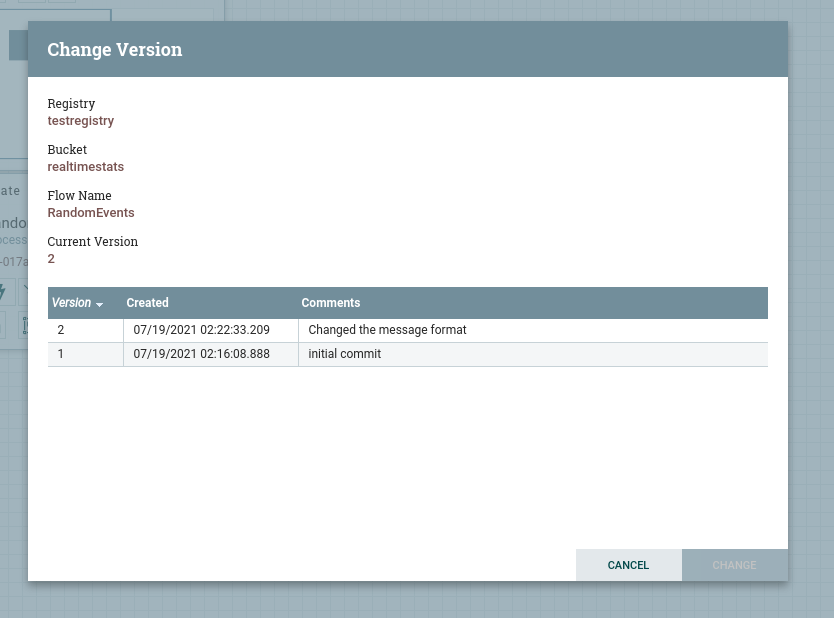
You can also check the version history from the Registry UI itself.
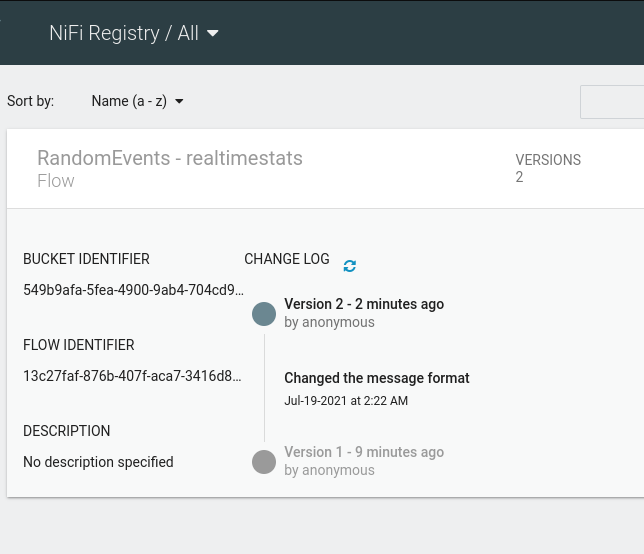
Quirks?
Yeah, a few.
With the design
- As you have already noticed, this design focuses on separating different environments entirely. However, the Registry component can easily be shared between environments. This can be done by either keeping the Bucket names different (ex:
realtimestats-devandrealtimestats-test) and perform the same import/export API calls between the Buckets, or just using one Bucket and using it as central place to pull from, for the non-dev environments. In fact, it seems from the documentation, that this is the user story Nifi project had in mind in the first place. However, depending on the set of requirements, these environments would have to be separated. This could be because of security concerns, compliance issues, architecture restrictions, or a strong desire to keep things separated. In any case, many of the above API calls do not change based on the design. - This approach does not allow changes to be done on the Flow definitions after the
devenvironment. Though this is the ideal way of doing things, business requirements, or time constraints could force local changes to be made on the (ex:)testenvironment. In these cases, it’s better to commit the changes and perform the migration tasks on those committed versions. - Nifi Registry’s user management features have not been taken into account. This is out of scope of these two posts.
With the script
- You may have noticed that if you run the above script again and again, the same version would get replayed on top of the existing version on the target environment. This is something we can’t avoid at the API level. Serialization that happens upon
versioning.export_flow_version()API call inserts UUIDs and timestamps that are unique to each operation. Therefore, there is no way (at the moment this post is being written), to compare an existing version and avoid an import if the contents are the same. We could hypothetically compare commit messages, however given how careless a normal developer is with commit messages, it’s entirely possible different commits would have the same commit messages. Therefore, this would have to be tolerated as something that can’t be overcome at the moment. - Commit replay itself is another issue. From the above screenshot of the
testenvironment version history, you can see that the timestamp of the commit is not entirely the timestamp the change was originally made at. The Registry level operation when importing a specific version is more like a git patch application than agit pull -r. You lose a certain set of metadata this way. - There are more edge cases where this script could easily break. There could be different Process Groups with similar names, and because of the way the
get_flow_in_bucket()API method operates, all of the Process Groups could return as part of the API call. Some parts of the SDK are still a bit brittle, so more exception handling may be needed.
This is just one way of performing this task. The decoupling between Nifi and the Registry allows different designs to be implemented based on organizational requirements.
The code and the config files referred to in these two posts are available at chamilad/nifi_cicd_poc repository. Please open an issue if you want to clarify anything.