Intro
I covered establishing a comprehensive cross-account backup strategy in AWS Organizations in the previous articles and videos.
However, as an architect, one of the most frequent patterns I come across in the real world in this space is organisations having an imbalance of backup and recovery strategies. This is when there is a really detailed backup process that includes all the production resources in the backup jobs, with encrypted and replicated copies, but having minimum or even zero effort in testing recoverability of the backed up data and having playbooks for such scenarios.
Most of the time what happens to cover the checkbox for recovery testing in security audits and internal process checks is to do a quarterly (or even scarier, annual) manual recovery check for a single file off the backup vault. This soon becomes a process for process’s sake and loses the real aim of testing if actual backed up data is recoverable. Furthermore, having an annual recovery test for an unrelated file does not help in establishing runbooks for Disaster Recovery (DR) scenarios. It isn’t even close to what you would do in a SHTF situtation. This is missing the entire half of a complete backup strategy.
So in short, you should
- frequently test your backed up data
- have runbooks for SHTF scenarios, and drill them
Without these two conditions, when something goes wrong (notice that I didn’t use if something goes wrong), your engineers are not going to have a proper idea on how to get back to normal. They will have to figure things out as they try to manage systems and people when both of these are screaming at their face. It will be that much harder to stick to your Recovery Time Objectives (RTO) and you will have no idea about the Recovery Point Objectives (RPO) because you have no idea how useful the backups are.
This article covers two areas in this subject.
- how to restore data from backups - should give you a basis to build runbooks
- how to do automated restore testing - should give you confidence about your backup strategy and the ability in DR scenarios
Setup
I’m going to use the same setup that I used in my previous article on setting
up the backup strategy with AWS Web Console. I have two accounts
workload_a where the original resources are, and backup where the
cross-account backup vault is.
workload_a account has the resources that should be backed up, and backup will
be the cross-account backup vault. If you’re unfamiliar with cross-account
backup concepts, refer to my earlier blog
post and the video on the subject.
There is a DynamoDB table called tracking in the workload_a account. There is also an RDS instance called mydb in the same account.
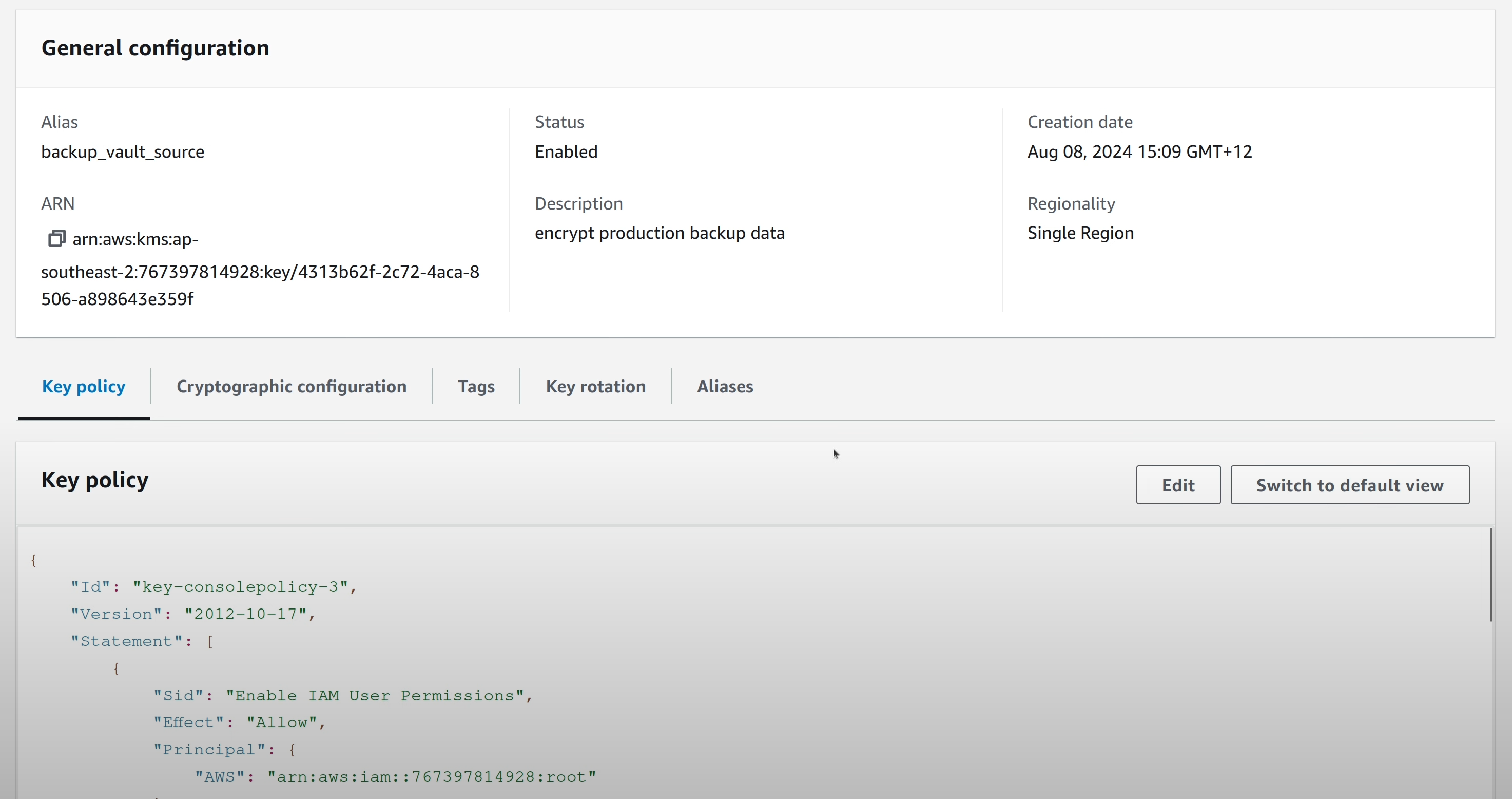
Both of these resources are encrypted at rest with the same KMS key.
A separate KMS key is used to encrypt the Backup Vault contents.
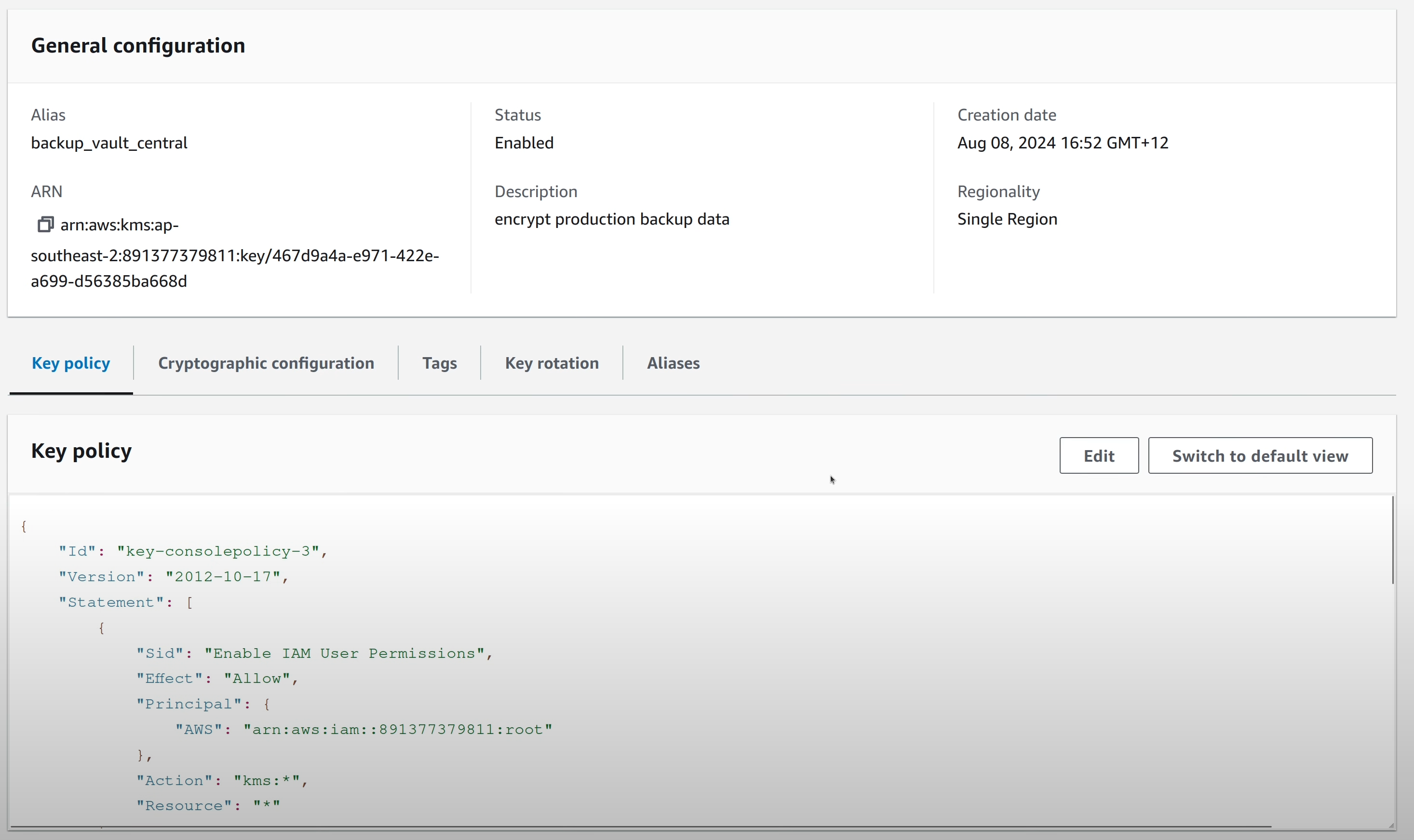
A similar KMS key is present in the backup account which can be used to
encrypt vaults in that account.
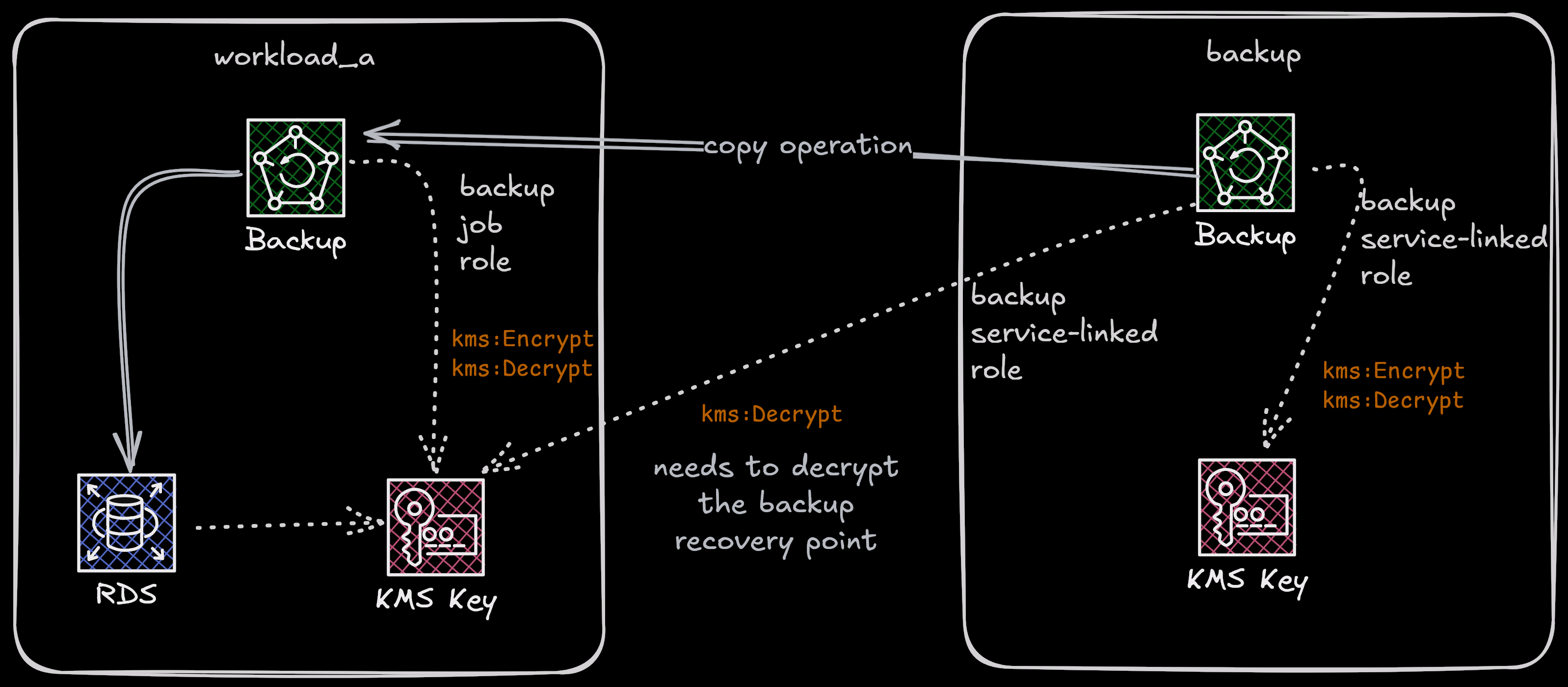
The following architecture is going to be used with this aritcle when restoring
data into the workload_a account.
After the last article, I have a few recovery points in both the in-account vault and the cross-account vault. In this article, I’m going to cover the following scenarios.
- Recovering data from an in-account vault
- Recovering data from a cross-account vault (when it’s really bad)
I’m going to perform these two scenarios for both the DynamoDB table and the RDS instance because they represent the two kinds of resources that AWS Backup handles with different ways especially when it comes to encryption.
Restoring a snapshot creates a new resource. Snapshots cannnot be restored into the same resource (to avoid data loss).
In-Account Recovery: DynamoDB
Data can be restored from either the resource backup lists or from the AWS
Backup Console. For DynamoDB for example, the backups made either by AWS Backup
or DynamoDB itself are visible in the “Backups” tab in the DynamoDB table view
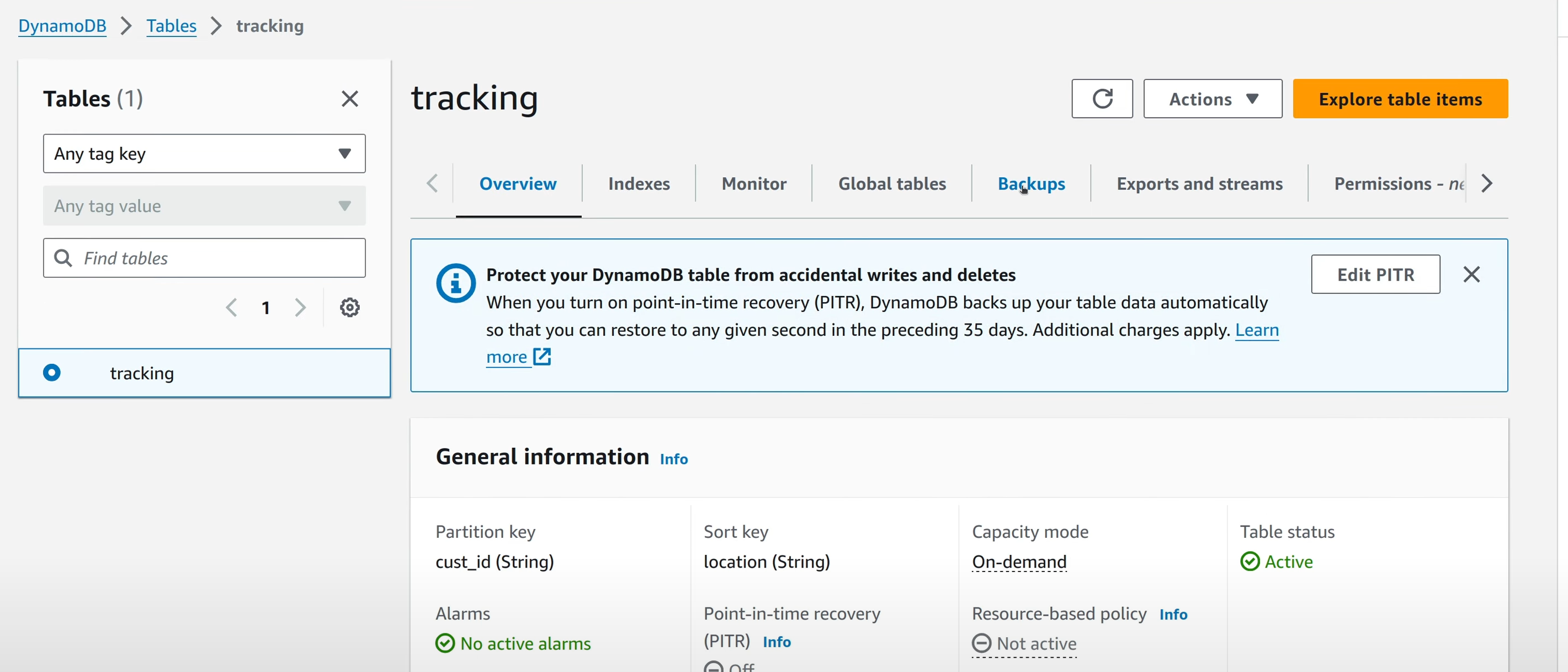
Only the snapshots in the in-account vaults are visible here. No external vault based snapshots can be directly accessed by this account.
The snapshots created by AWS Backup have the arn:aws:backup:<region> prefix
whereas snapshots created by DynamoDB independantly will have the prefix of
arn:aws:dynamodb:<region>.
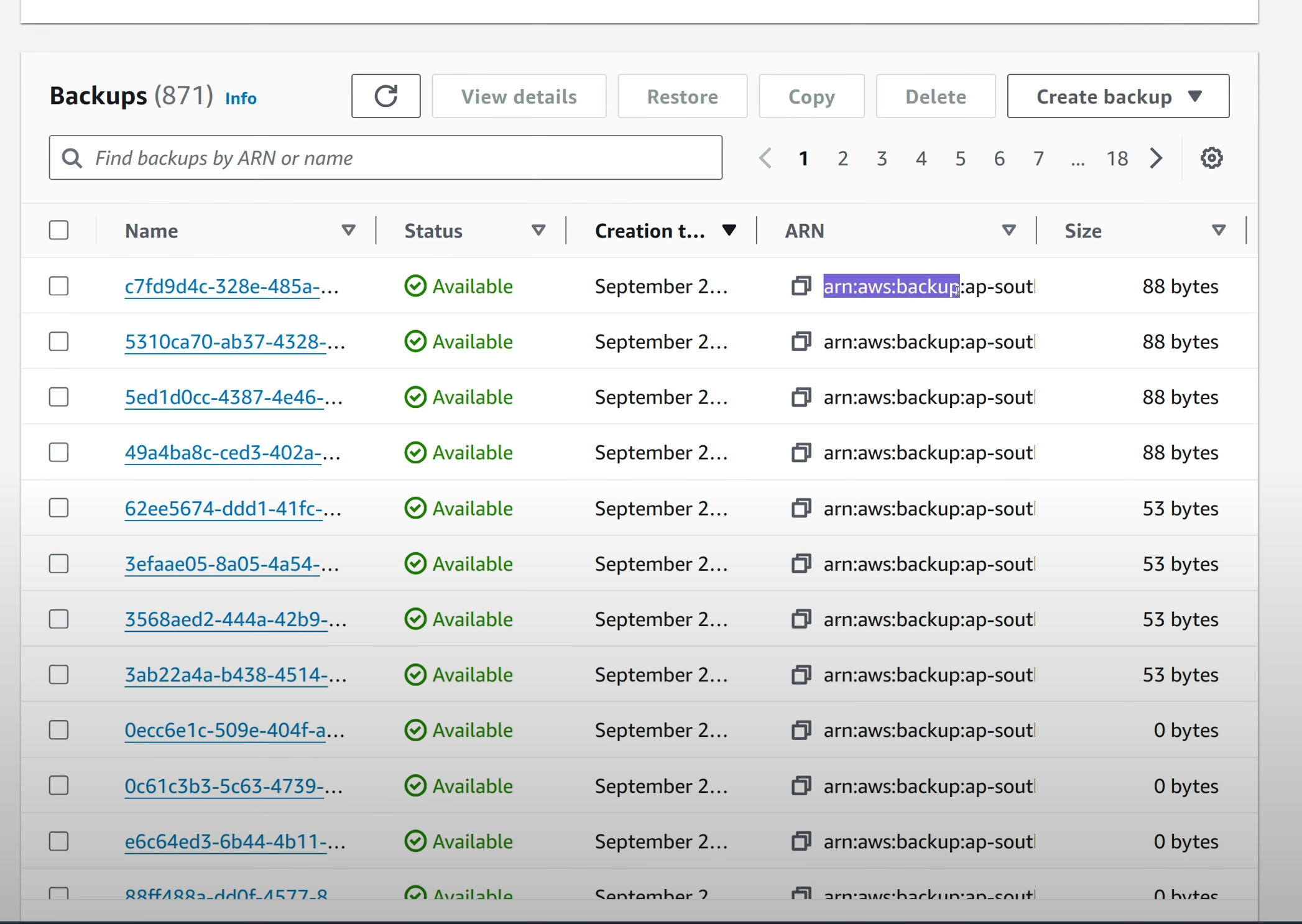
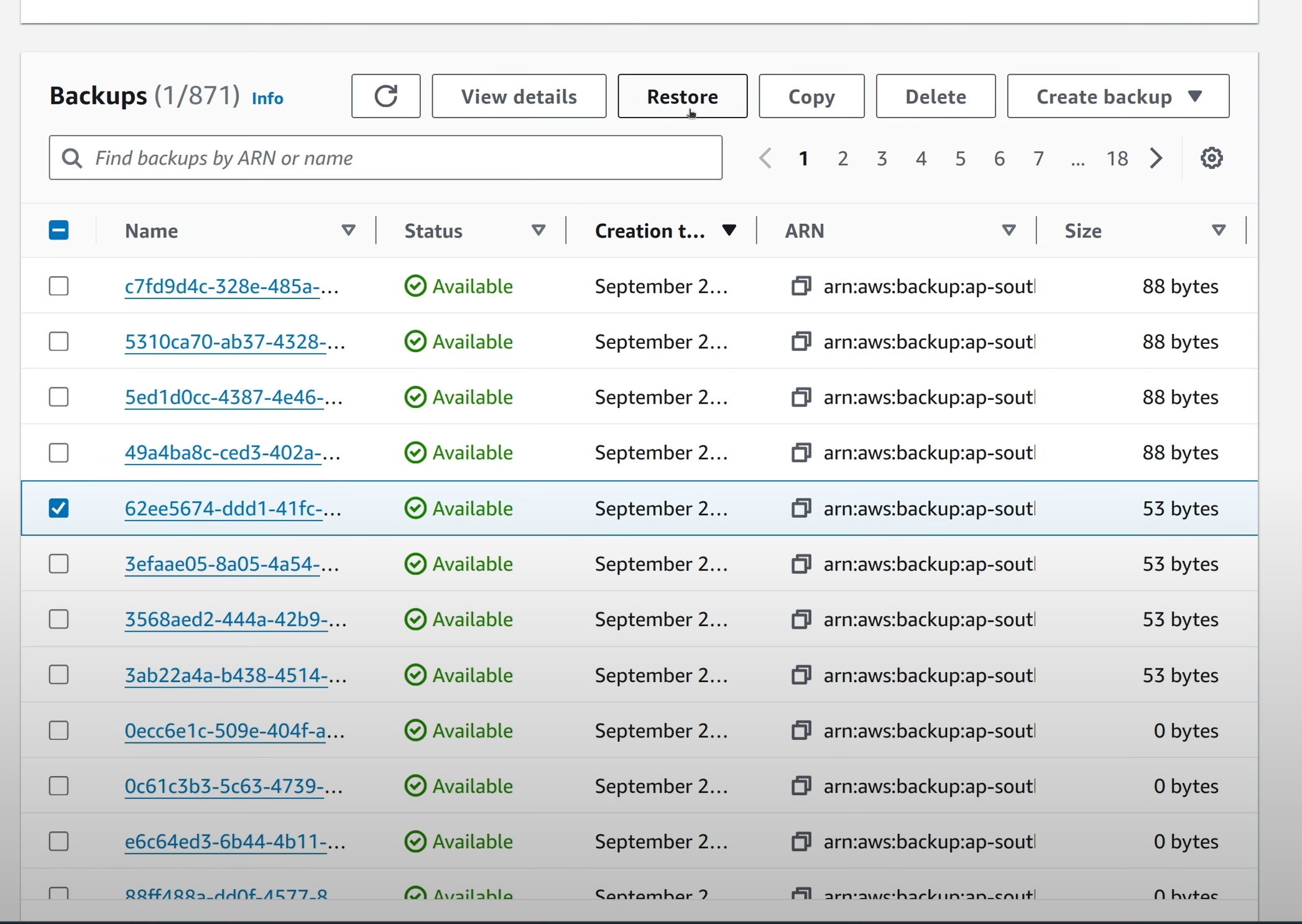
To restore a snapshot, select the desired entry and click on “Restore”.
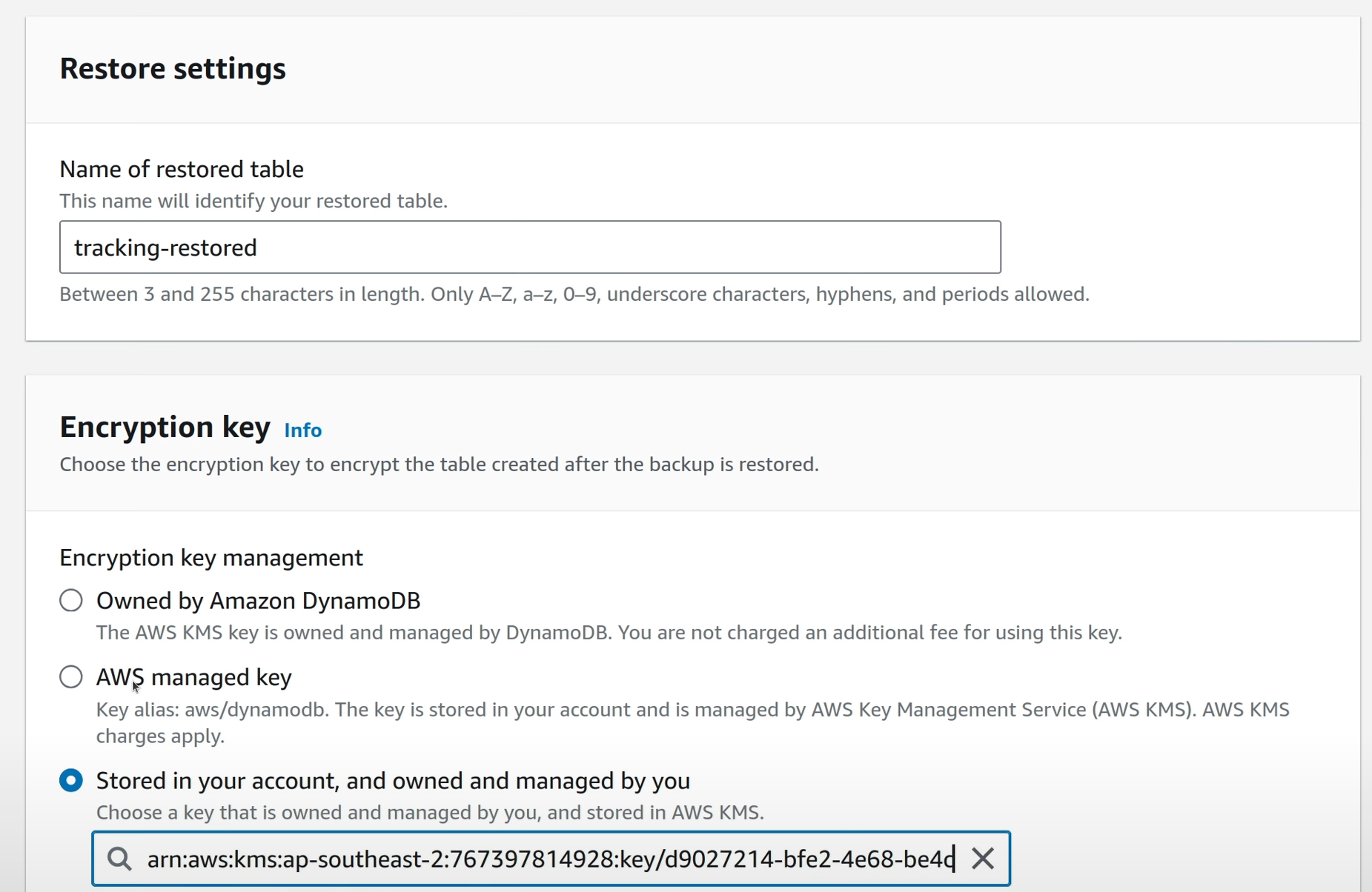
In the provided screen, define a name fore the new resource that will be created with this snapshot, and select the encryption settings for the new resource. With DynamoDB, since the encryption of snapshots is handled by AWS Backup itself (more on that in the previous articles), the encryption settings for the new resource can be different from the original resource.
Also select the Role that AWS Backup will use for the restore action. This can
be the default Role (advisable since it’s just about the permission policy that
is attached to the Role. The default Role has the
AWSBackupServiceRolePolicyForRestores AWS managed policy with it and this is
the most convenient way).
When “Restore” button is clicked, a Restore Job is created in AWS Backup. This can be viewed by going into AWS Backup console -> Jobs -> Recovery Jobs tab.
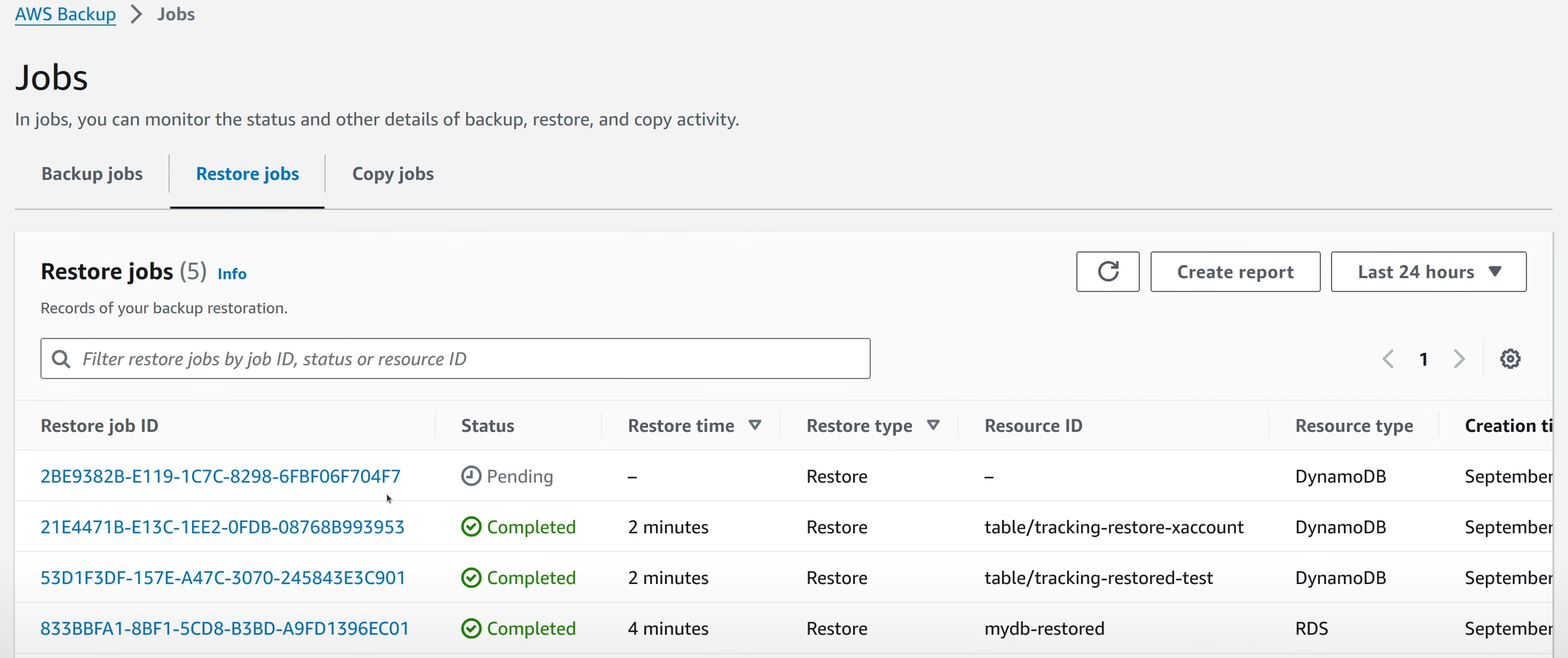
This job is in the pending state, and will complete with the new resource being created.
After the job goes into “Completed” state, a new DynamoDB table with the data from the snapshot can be seen.
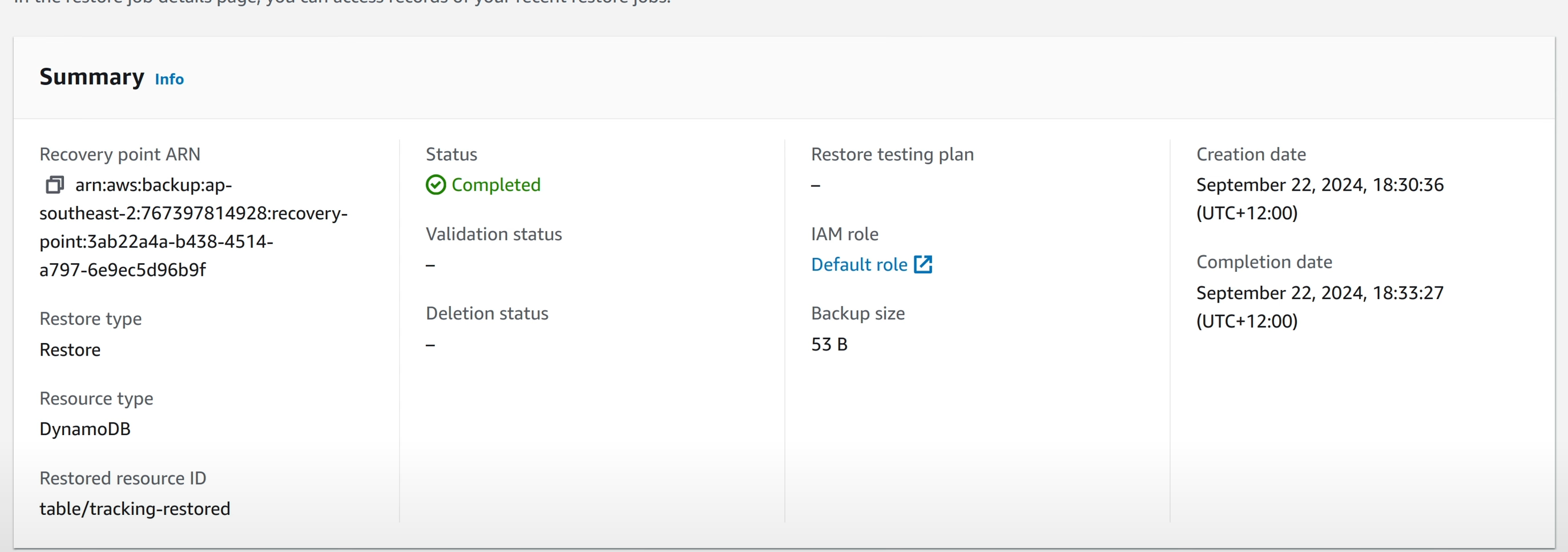
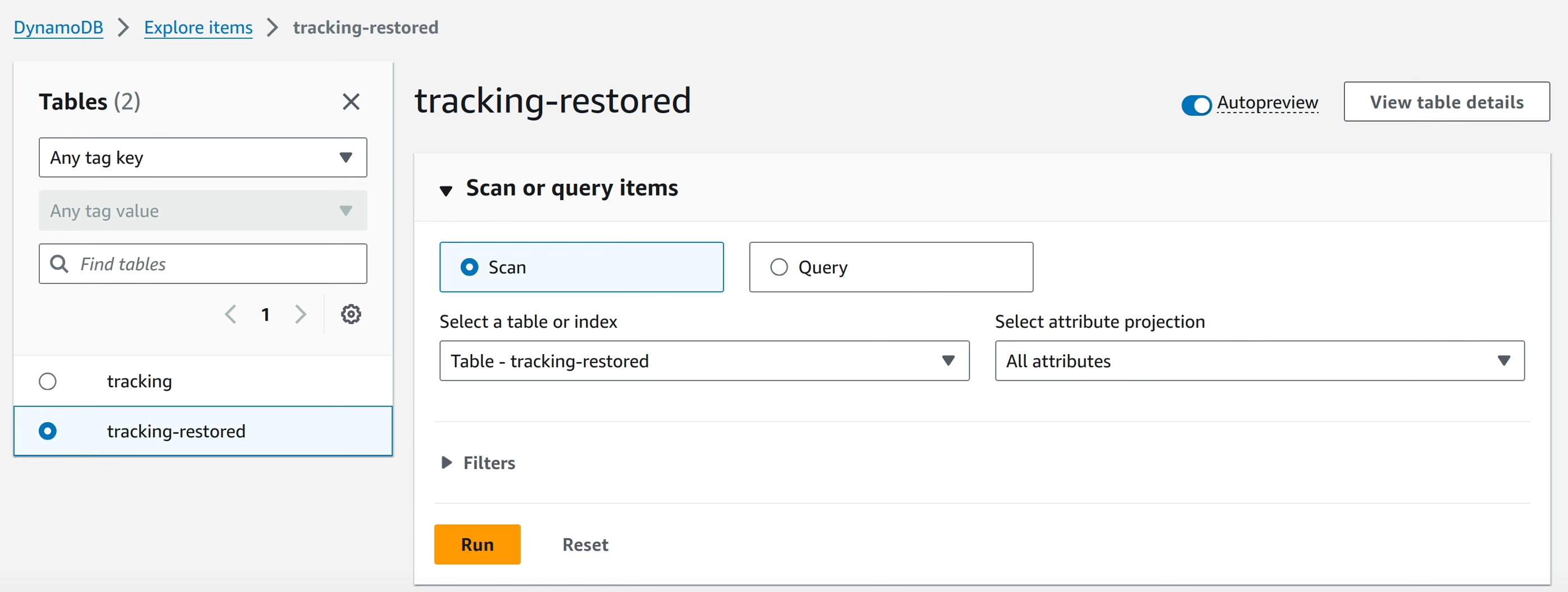
In-Account Recovery: RDS
For RDS, let’s use the AWS Backup console based method where you’ll see the snapshots created by AWS Backup listed in the vault contents.
Go to the AWS Backup Web Console -> Vaults -> Select Vault -> Scroll down to Recovery Points section.
Since the vault is the destination for snapshots from multiple types of resources, the snapshots for the specific RDS instance will have to be filtered in the UI.
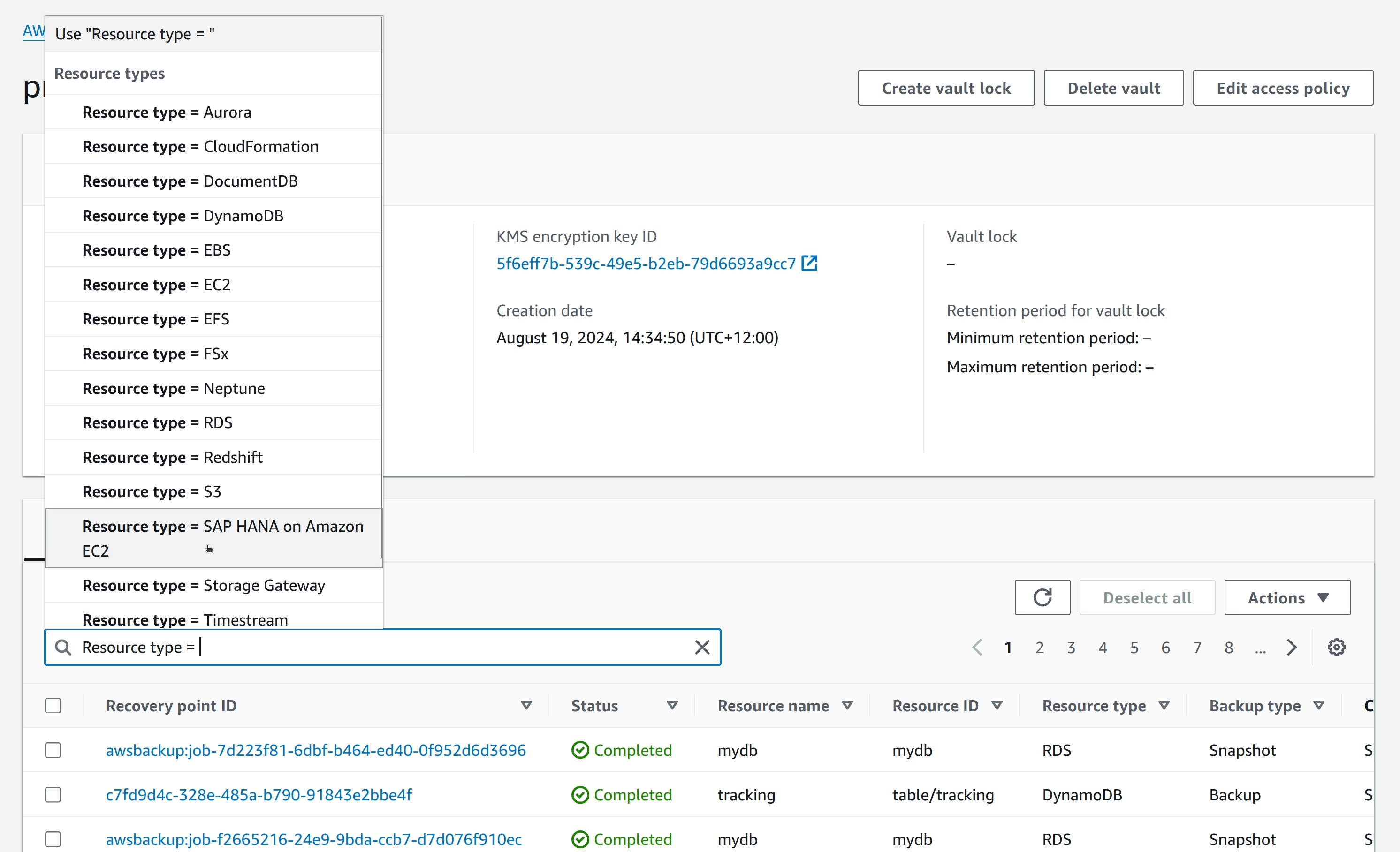
Select the desired snapshot and select Actions -> Restore.
Like DynamoDB, the snapshot gets restored to a new RDS instance. New instance details can be changed in the restore screen, however unlike DynamoDB, the encryption configuration doesn’t offer a lot of flexibility. The same KMS key needs to be used for the new instance, because RDS handles encryption outside of AWS Backup during backup and restore.
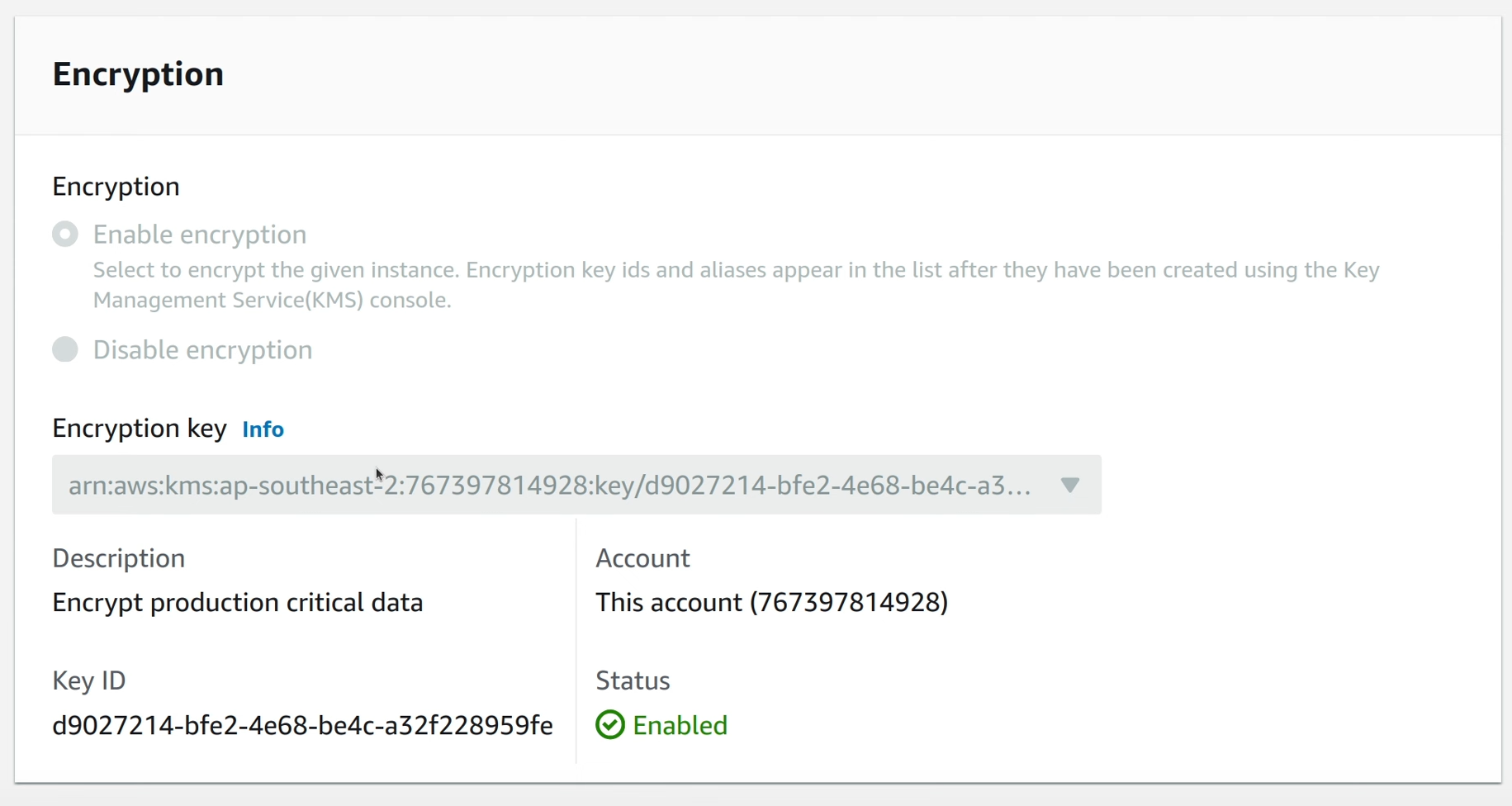
Clicking “Restore” creates a Restore Job in the Jobs console, which can be monitored for successful resource restoration.
Same as the DynamoDB table Restore Job, when this Restore Job goes into completed state, a new RDS instance can be seen in the list.

Cross-Account Recovery
Like I mentioned in the last article on this series, to recover from a snapshot, it has to be in the same account vault as the target account. Snapshots in a cross-account vault cannot be used to restore resources.
So, in case the source account vaults have been deleted somehow or the snapshots are needed to spawn new instances in a different account, they have to copied to the new account vaults first. For this, we can utilise the same type of job that was used during the cross-account backup job, called Copy Jobs.
Something that needs to be repeated from the last article is that for this copy job to successfully happen, the target vault (what I called the source vault in the last article, yeah, it’s a bit confusing) needs to have the proper vault policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Allow central account to copy into prod",
"Effect": "Allow",
"Action": "backup:CopyIntoBackupVault",
"Resource": "*",
"Principal": {
"AWS": "arn:aws:iam::<central account id>:root"
}
}
]
}
If this detail is unclear, please refer to my last post on this, where I explain what a vault policy does and how this allows cross account copying of snapshots.
To copy a snapshot to a vault in another account, go to the central account vault (in my case, it’s in the backup
account), select the desired recovery point, and click Actions -> Copy.
The resulting screen provides a few options, including a useful option to copy the snapshot back to the source account vault. This can be used in a disaster recovery scenario (if the source account isn’t fully compromised of course). However, the snapshot can be copied to a completely different account as well.
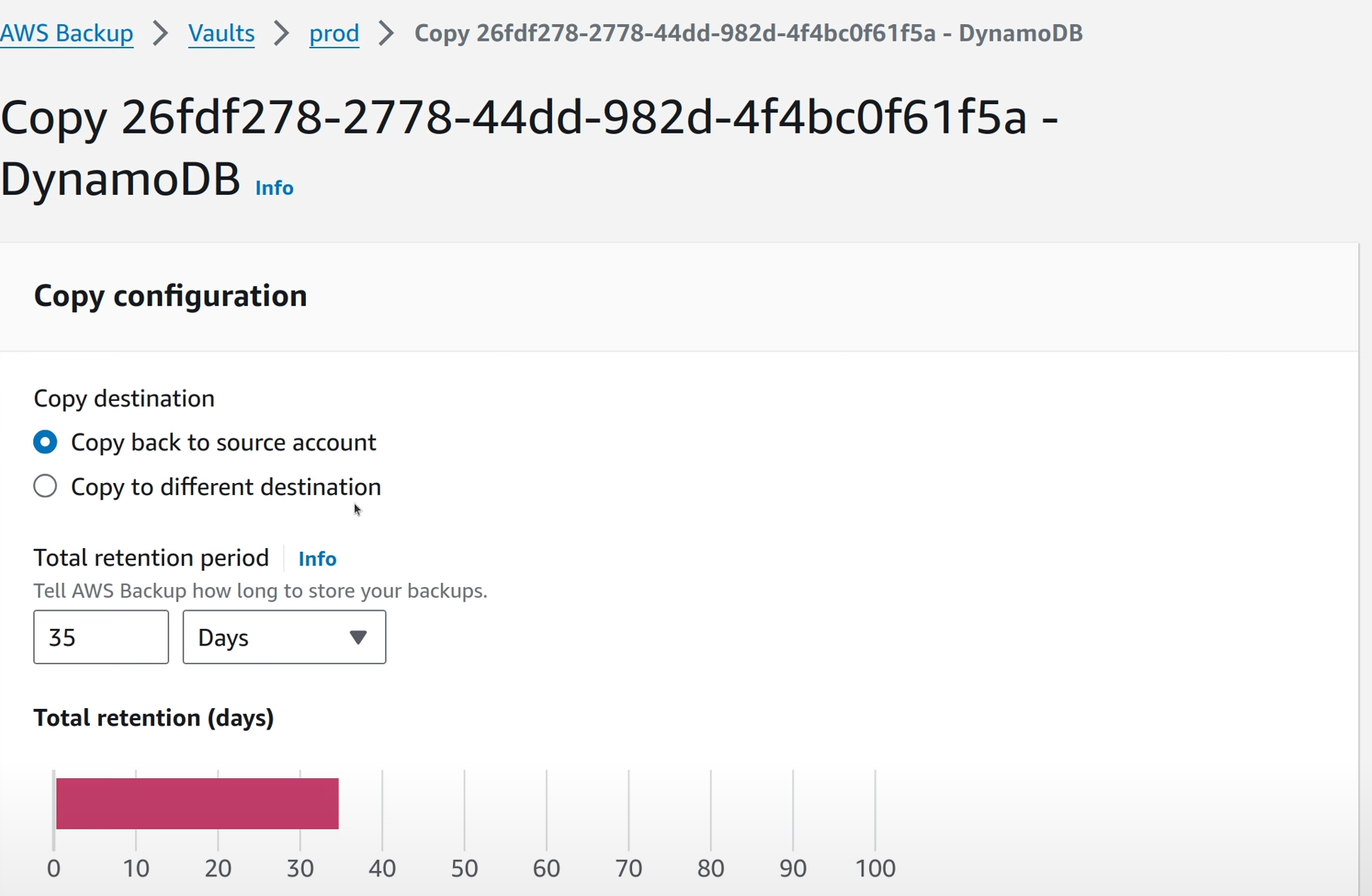
Like in the previous step, define the IAM role to be used for the copy job.
A Copy Job will be created and once this is completed, the snapshot will be available in the destination account vault (previously known as source account vault) to be used for restor jobs.
In the target vault, the snapshots that were copied over can be filtered by the Source Account field. Only the snapshots that were copied over from a different account has this field attached to them.
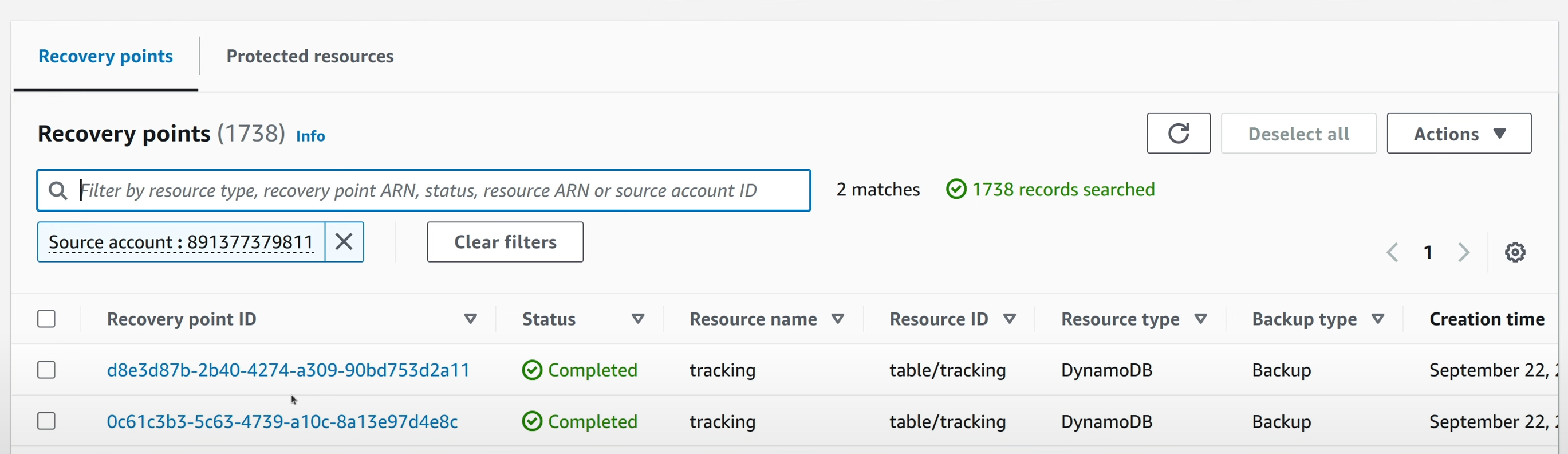
The snapshot details will also have a section called Copy Summary, if it was a result of a copy job.

This snapshot can then be used to restore data to a new resource by following the same steps as above.
Continuous Restore Testing
The above workflows cover data recovery that is done manually, usually when there’s a real world need to do so.
However, there is the additional need to make sure that backup data is valid and restorable when needed. This assurance should be automated and periodical, and should raise alarms when it fails.
AWS Backup offers a feature called Restore Testing which covers all of these requirements. Before this feature was introduced, automated restore testing had to be done manually by writing custom lambda functions. With the new feature, a restore test plan can be written just like a backup plan is, and can be scheduled to repeat and notify tests to be run on the restored data. These automated tests can generate reports that can be both used as useful indication of the backup strategy and provided as evidence of effective implementation of a DR strategy during information security audits.
Let’s create a Restore Testing plan for the DynamoDB snapshots that are taken by AWS Backup.
In the AWS Backup console, go to Restore Testing and click on Create Restore Testing Plan.
Provide a name for the test plan and define the schedule for the tests to be run.
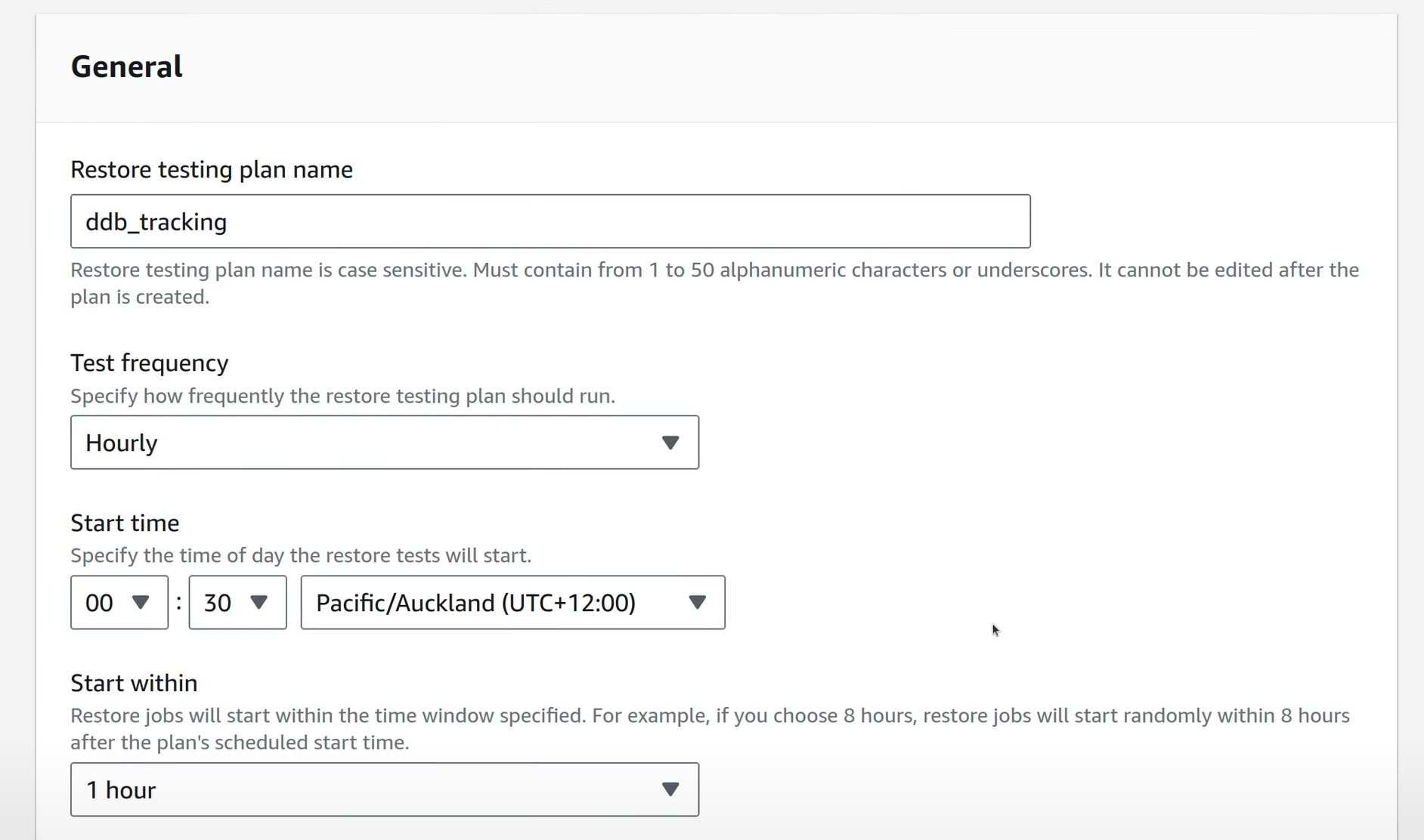
AWS recommends that restore testing is done on a non-prod separate account so that you wouldn’t overwhelm limits and quotas and affect production workloads unintentionally. For this demo, I’m going to use the same account, as this is a productionising detail.
Also select the vault and how the snapshots should be selected for restore testing. It can be either a random selection from a time frame, or the latest snapshot within that time.
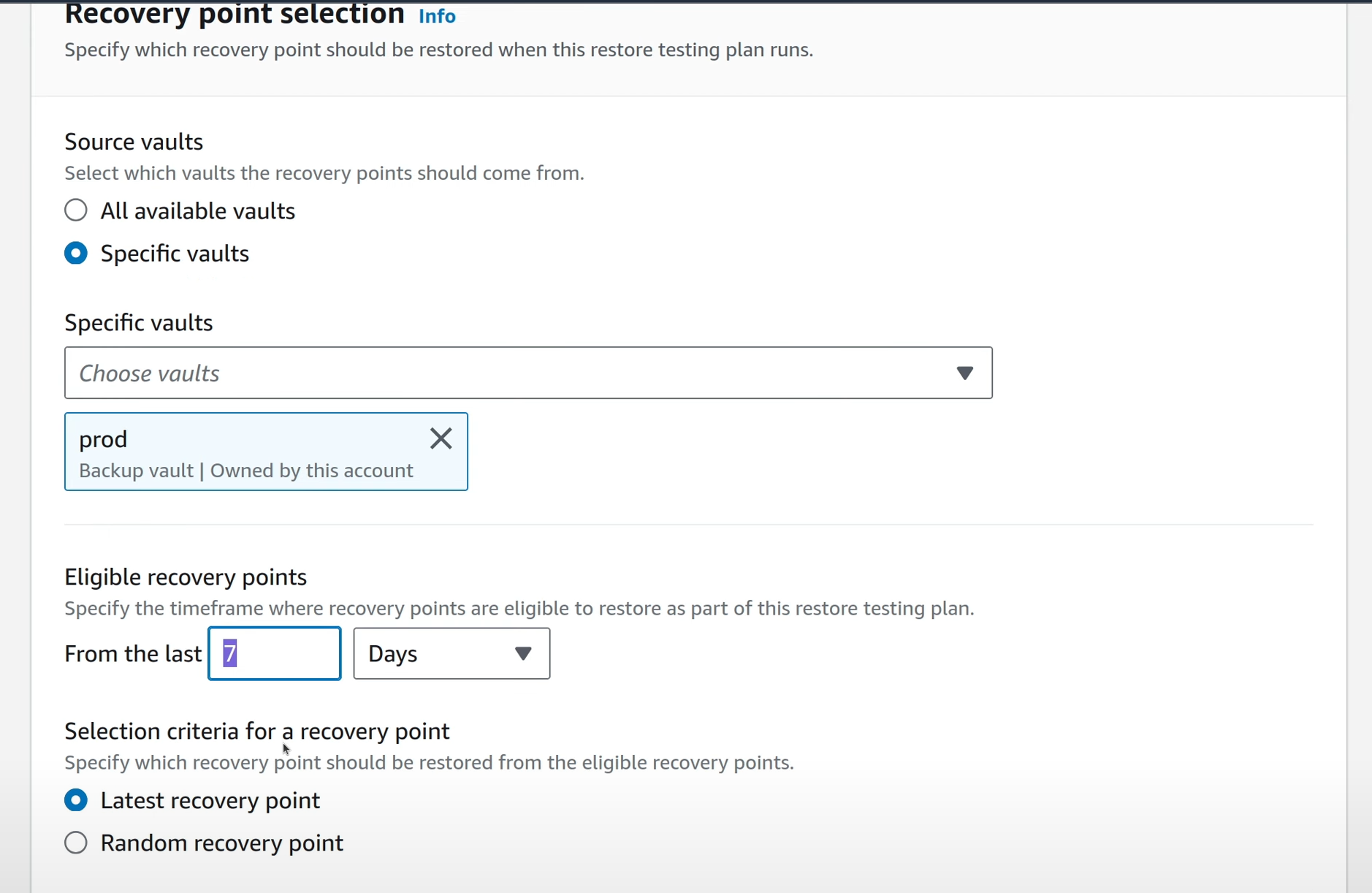
In the next screen, assign resources to be tested (or more specifically, resources of which the snapshots will be tested), just like resources were assigned during the creation of the backup plan.
Additionally, specify the retention period for the resources created by the restore testing plan. They are usually immediately deleted, but it can be configured to retain them for a small time window to do manual testing and other inspections if needed.

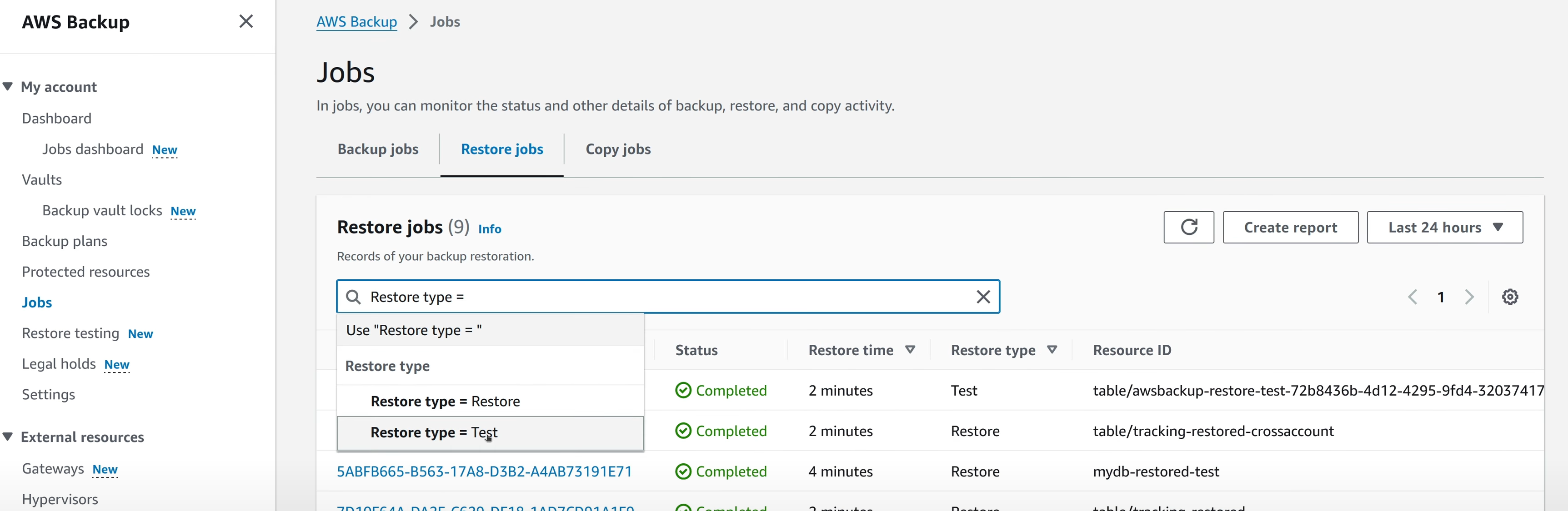
Once the Restore Testing plan is created, you can monitor the status of the test runs by checking the Restore Testing Jobs section in the same page. You can also view the Restore Job status by going to the Jobs view -> Restore Jobs tab and then filtering by “Restore Type == Test”. Normal restore jobs have “Restore” as the value for this field.
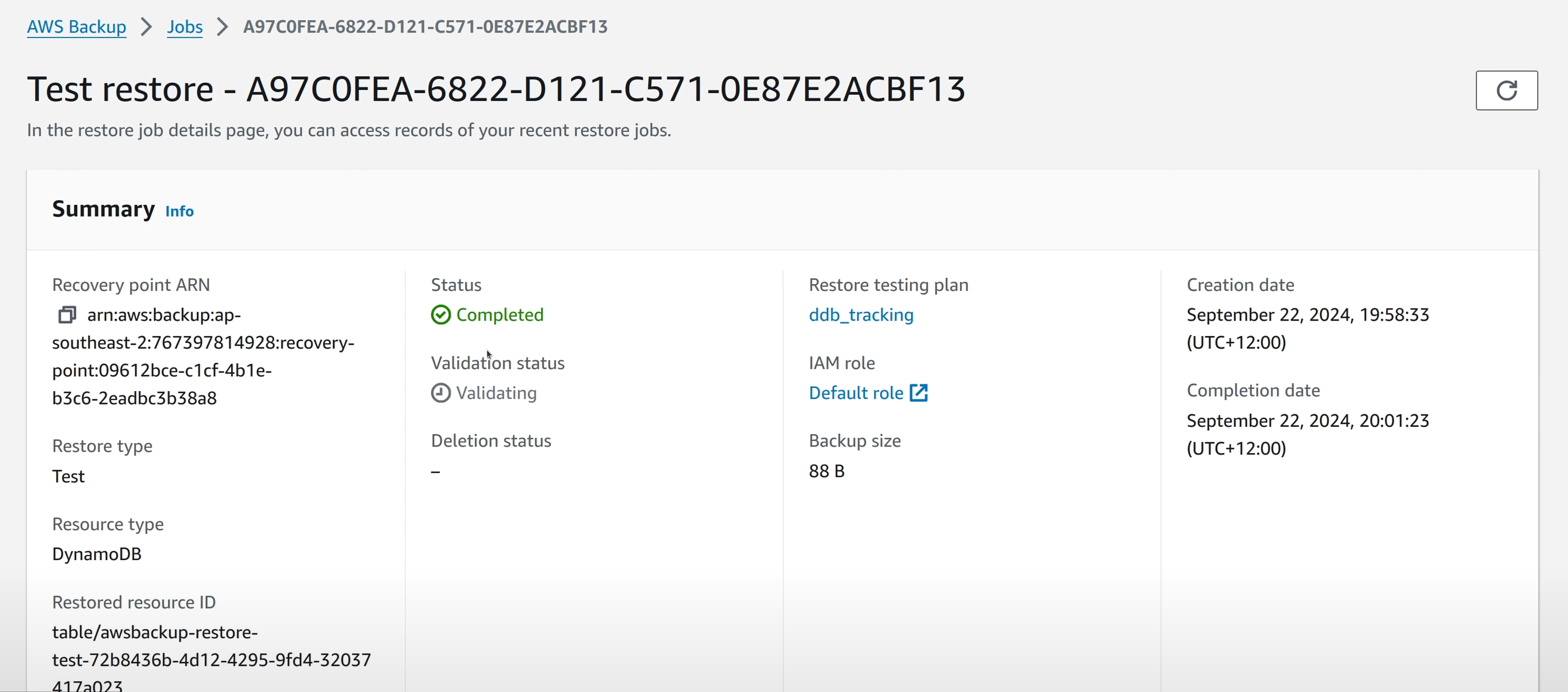
In the job details, there’s a field that shows the validation status of the restore test. This is a basic validation test of the resources that are being created as part of the restore test. If more “manual” in detail tests need to be done, they could be triggered based on the restore job status event in CloudWatch EventBridge.
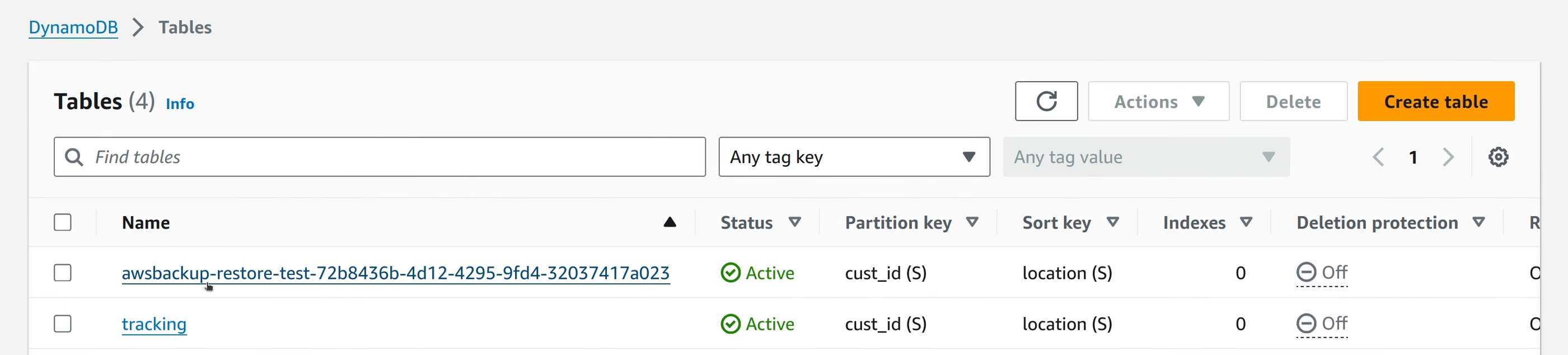
If you configured retention of the restore testing resources, you could see the DynamoDB table that was created by the restore testing job in the web console.
You can build CloudWatch alarms to notify you if a certain threshold is broken for the number of failed restore jobs. This could be vastly useful than waiting for the yearly manual test to complete which doesn’t even test the actual snapshots (I’ve been part of the process that provided evidence like this during ISO27001 recertifications, and I’m not proud of it).
Providing Assurance for Continuous Restore Testing
If you saw my article on Information Security Compliance on AWS Solutions (or my twitch talk on the AWS From the Field channel) (or my AWS Community Day NZ 2023 talk on the same subject) you know that I like approaching compliance on the three-lines model of managing -> overseeing -> providing assurance. I also believe the last step of providing assurance is massively under-scrutinised by the scale of the cloud and lack of familiarity of the cloud environments by the information security auditors. AWS services like Audit Manager can be a huge relief in cloud information security compliance audits by their ability to provide auditor friendly reports on all parts of your cloud footprint.
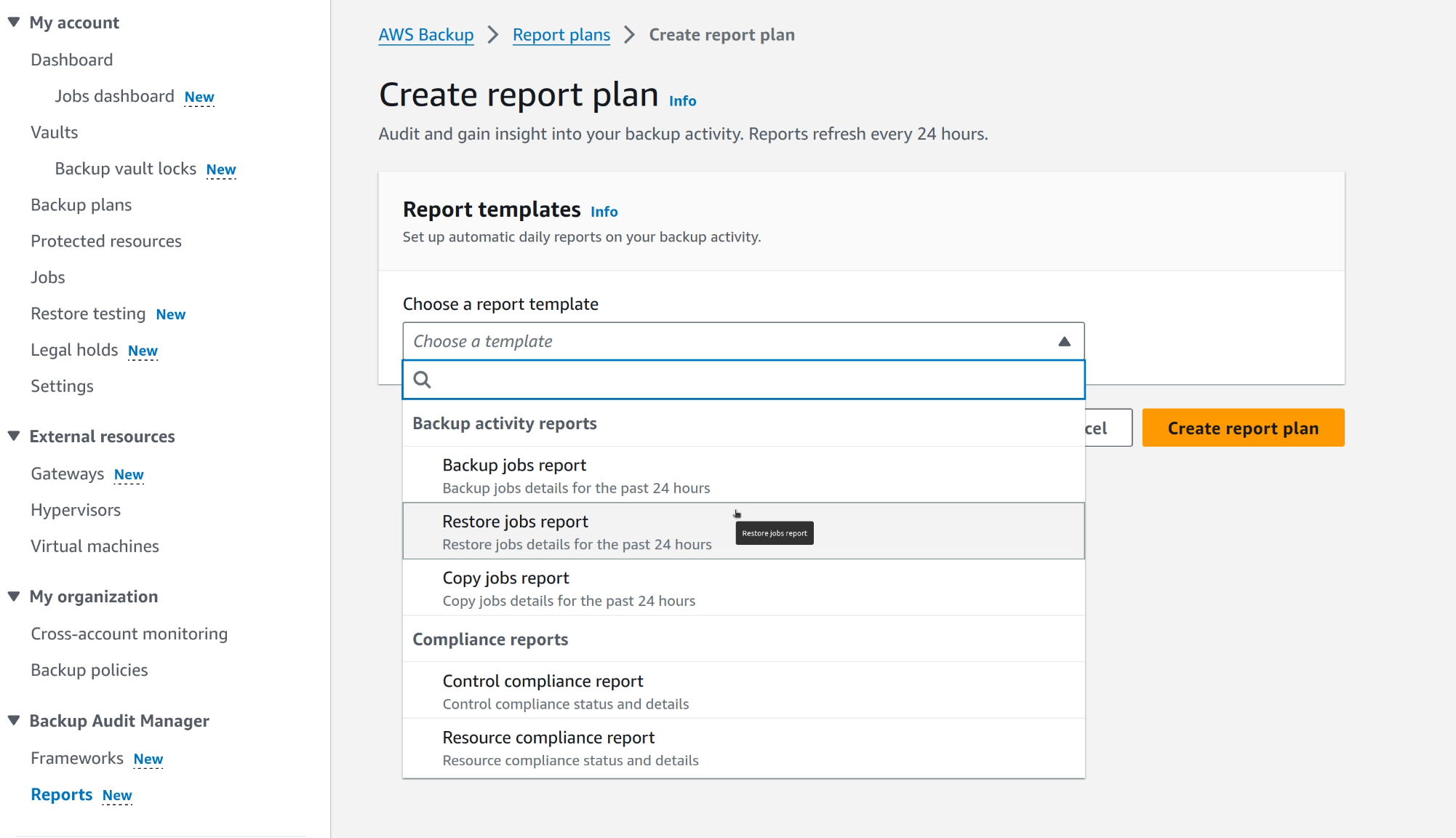
AWS Backup Audit Manager is a similar, supplementary, feature that can be used to generate reports that can provide a comprehensive picture of the status of the backup and recovery implementation.
Backup Audit Manager can generate different types of reports for backup and restore activities or more compliance oriented reports if the overall status needs to be communicated. This helps you achieve both overseeing capability on top of the ability to provide up to date accurate evidence of your compliance status.
tl:dr;
- Write runbooks on how to restore from your backups and regulary run drills for those runbooks (and improve them if gaps are found)
- Automate the testing of backups, ideally using features like AWS Backup Restore Testing
- Use features like AWS Backups Audit Manager to achieve overseeing capability of risk mitigation status for DR scenarios and to be able to provide accurate up to date evidence of your work on achieving compliance