Server Immutability is an interesting concept that I managed to come across when I first started playing around with Containers. Interestingly, it’s often used in conjunction with Containerization because of the use of startup file systems (or Images). However Server Immutability is something that goes beyond simple Docker images.
What is Immutability?
Immutability, when it comes to server instances, is not changing a once deployed instance. Any change that should be done, has to be done in a new version of the instance image and the old running instances should be replaced with the instances spawned from the new image.
The perfect example of this is the Image-Container flow (ex: in Docker).
- Create a Docker image (
myapp:v0.1) using a Dockerfile which creates a starting file system along with other image metadata - Spawn a Container instance from the above created Docker image (
myapp:v0.1) - A new configuration change is submitted
- A new version of the image (
myapp:v0.2) containing the config change is built - Replace old Container with a new Container spawned from the second Docker image (
myapp:v0.2)
We never did any changes to the running Container in the above scenario. In other words, a running server instance is immutable, because any mutation comes from the base file system, or the Image, from which the server instance started from.
The VM equivalent of this scenario would be creating new snapshots from the previous one with the configuration changes in question included, and spawning a new VM instance from the new snapshot to replace the old VM.
Why
This is all neat and nice, but why would we want to go for server immutability when we could just maintain an instance? A few reasons are of crucial importance.
- Verified consistency
- Codified configuration
- Well defined and well adhered processes
- Easier update roll-outs
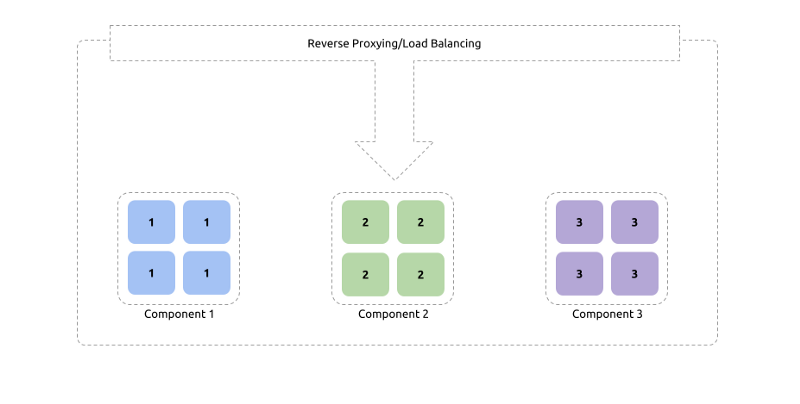
Let’s take a sample deployment consisting of multiple component clusters.
Verified Consistency
For a guaranteed consistency of functionality, each instance of a single cluster should have exactly the same artifacts and the same configuration. This sounds easy to be done when the initial stages of instance spawning are considered. With a fair amount of Configuration Automation options available, initializing a set of nodes with an identical set of artifacts and configurations can be easy. Martin Fowler calls these Phoenix Servers.
However, Configuration Automation alone cannot guarantee consistency at a given moment. Details like OS level configurations, patches, and tweaks can be addressed by a certain degree of scripting but not without sacrificing compatibility. Configuration Automation tools only address the problems in the component configuration space. They rarely venture in to the infrastructure layer, and even when they do, it’s without full effect. For an example, Configuration Automation tools like Puppet or Chef do not successfully address to need base infrastructure like networking for server instances to be spawned.
On the other hand opening up doors for continuous runs of the Configuration Automation tool opens up the possibility (and temptation) to perform manual ad hoc changes on the nodes. This would include tasks like temporary config changes, certificate and key store swaps, and simple OS level upgrades. This introduces what is known as configuration driftwhich essentially means the configuration across the cluster has (slowly) drifted away from the initial, intended state.
The Immutable approach dictates that no change should be done on the Servers themselves.
For example, if there is a critical OS level security patch to be applied, the only way to get a 100% guarantee that the patch was applied uniformly is to spawn all instances from a base image that already has the patch. Here, the patch application (i.e. the mutation) is done on the base image, not on running nodes. The perfect example for this is the Amazon AMI.
Codified Configuration
Take a look at our deployment diagram. Do we know the maximum number of files allowed to be open on the nodes in the Component 1 cluster? We can open a shell to one of the nodes and get the number by issuing a command. But how do we know if it’s different or the same across the cluster?
What if someone finds out the above number is not what is desired, changes it then and there (and somehow manages to replicate the action across the cluster), and cause a chain of events that lead up to a catastrophic production failure? Do we have a trail of the changes done to the configuration of the cluster (even if the changes are uniform across the nodes)? Are we able to find some kind of documentation which rationalizes the configuration change (or the number of configuration changes) done on the deployment? Wasn’t there a chance for a more senior person with more experience to advise on the change before it could be effectively applied to production?
At a given moment can we get an understanding of the currently running specification without having to explore each node?
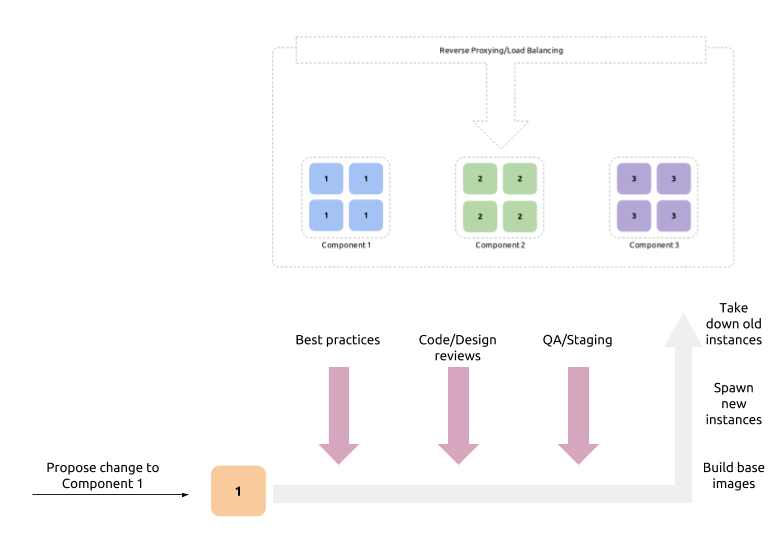
Configuration Automation practices solve a part of this problem by codifying the component configuration steps. Properly set up process make sure that any change that has to be propagated to the live system is code reviewed, approved, and has gone through proper test and staging cycles.
Adhering to Immutability forces the same to be done throughout the stack, from low level configurations to the higher level product artifacts. To produce starting points (base images, network configuration, load balancing) there should be some kind of written instruction set. These can be version controlled, reviewed, processed, tagged, and released.
For Amazon, AWS CloudFormation, HashiCorp Packer, (and) or Terraform fulfills these requirements. They are designed to worked on through collaboration. This enforces practices similar to software development where easily identifiable issues are proactively found in the code before it’s rolled out to production.
Well Defined and Well Adhered to Processes
Coupled with the above aspects, sticking to Immutability demands well defined processes to be in place, for better agility. Without proper processes Immutability quickly becomes unmanageable with more time wasted on manual tasks than automation.
Codification enforces better insight into code, at the same time enabling a larger part of the deployment process to be automated, with a CI/CD pipeline in place. A certain amount of tests can also be automated, bringing an acceptable level of assurance on the stability and performance of a new change.
The tools and technologies that enable Immutability bring their own recommended best practices, which are often the product of years of collective experience of the related communities. A relatively new IT section with less experience can easily adopt them, collecting their own set of experiences during the process.
Well defined well practiced processes make it easier for third party vendors to add support in terms of patch propagation, upgrade pipelines, and configuration recommendations. This is drastically in contrast to ad hoc processes that vendors often do not recommend and do not want to get involved with. What it essentially means is that the team would be able to focus on the business problems more, than focusing on the potential gaps between the vendor support model and the IT processes.
Easier Update Rollouts
With the processes and practices in place, Immutability effectively sums up a single control point for changes to be introduced. This makes it easy for vendor updates and upgrades to be introduced, tested, and rolled out to live systems.
Because of codified configuration the constantly practiced processes, all technical stakeholders have a chance to be up to date with the current configuration and their design rationales. This makes it easy to see and predict the impact of proposed changes, because now there are several members of the team with knowledge of the complete deployment, than just one (may be disgruntled) Devops engineer, who would have a better chance at seeing that the load balancer rule change proposed to be introduced will certainly break the multi-region story of the deployment.
Once the changes are approved and released, the rest of the roll out process can largely be automated, with monitoring, health checks, and alerts built into the process to update stakeholders on the new feature releases.
These are the most compelling arguments related to following Server Immutability for medium and large scaled deployments. However, Immutability is not a silver bullet (like any other term in this space).
Why not
Like mentioned above, Immutability demands best practices and processes to be implemented, with more focus on DevOps than plain old system administration. This effectively requires more planning, bootstrapping, development cycles, that may not be suitable if your
- deployment is small scaled with a few instances, may be even one or two per cluster
- deployment does not involve complicated technology stacks like Container Cluster Managers
- deployment is static with no drastic changes planned to be introduced in the recent future
- timelines are restricted that require quicker deliveries with a reasonable level of fragility
- team lacks initial knowledge to research and adopt related tools and technologies
Conclusion
With the proliferation of Microservices and Cloud adaptations up to Function as a Service level break downs, there are bound to be tens (may be hundreds, or thousands) of component instances running at a given time, per cluster. These will need guarantees and the agility that Immutability provides. This is the ground where the true power of Immutability principle can be utilized.
Written on May 17, 2018 by chamila de alwis.
Originally published on Medium