What should be your concerns for WSO2 on Docker?

Deploying WSO2 products on Containerized platforms is a well-tested well-resourced activity. There are various resources available to deploy WSO2 products on Docker, Kubernetes, CloudFoundry, AWS ECS, and Apache Mesos, both officially and unofficially. However, designing a Docker image so that optimal non-functional traits like performance, operational efficiency, and security is a separate topic in itself.

Docker, being both a DSL and a utility tool for Container image packaging, can be written in several different ways keeping various operational goals in mind. These approaches vary from an all files and configs pre-baked end to another end where almost everything, except a tiny helper layer, being mounted at Container run-time. However, not all these approaches are suitable for a WSO2 deployment, and figuring out these details can be a daunting task, especially at an earlier phase of the deployment. Therefore, it’s important to have a set of common guidelinesthat can help determine which approach to take in each case. I emphasize the word guidelines because these are only them, not hard rules or must-do’s in every deployment. There is freedom for the user to stray away, as long as the compromises made in doing so are understood.
The Range of Options
The strategies for designing a particular Docker image can be a per-scenario basis one. In one end, all the files needed are packed into the image itself at build time, and Container creation does not have any additional tasks to perform other than server specific runtime configuration. In this case the Dockerfile and the builder scripts will be heavy with artifact copying, file configuration, and handling various runtime differences at the build time itself. Most of the times, even Configuration Automation tools like Puppet or Ansible may also be involved. For a WSO2 deployment, this would make use of Puppet and Ansible modules for WSO2 to pre-configure every minute detail of the product at the time of the image build.
The downside of this approach is that since products, specially WSO2 products, can contain a rather long list of configuration options, the iterations to get a minor configuration detail to a running deployment could be more than what is preferable in terms of operational efficiency. Docker image builds could be time consuming, especially if the build cache is not being effectively utilized. Furthermore, if the particular image is large in size it occupies on the disk (collectively), then iterative images could take considerable time to be downloaded to running compute nodes.
On the other end is the approach where only the bare necessary files are packed into the image at build time. This in turn will require the Container creation process to either create or mount necessary file based artifacts based on runtime parameters. In this case, the startup scripts that get executed as part of the ENTRYPOINT instruction could be heavy and complex since it has to leverage various inputs and possibilities for those inputs to result in the desired function. This can soon become too complex to debug or develop upon since almost always what carries the weight here is a Bash or a PowerShell script. However, this approach is the most Ops-personnel friendly (note that I only emphasized personnel and left out Ops) one since no build jobs or image downloads have to be done in order to propagate a new change to a running deployment. Configuration Automation tools may or may not be involved in this layer. However, since they tend to be time consuming and heavy in operation, they do not go well with the Containerization principle to have as small startup times as possible. In addition to having a complex startup flow, this approach can also result in file lock and data conflicts when the same set of files are shared between different instances of the product. In WSO2 deployments, there potential points of conflict are configuration files, instance local databases, deployable artifacts, indexes, and logs that need to be separate between instances. If everything is mounted and shared between instances these will eventually result in conflicts and corrupt a deployment beyond all recognition.
It’s obvious that a specific user story will require the selection of an option somewhere between these two ends of the spectrum. Following are a set of principles that can help deciding where to place your approach between them.
Parent Image
WSO2 products are supported through various Operating Systems, including Windows, several Linux flavors, and MacOS. Out of these, Linux flavors such as Ubuntu, Debian, and RedHat family OSs are supported readily. Though other Linux flavors are not heavily tested upon, as long as the core dependencies of Java and Bash are supported, majority of the use cases should be running without any problems.
Selecting a proper parent image is a multi-faceted task. Since WSO2 products are based on Java, they cannot be run without an initial file system and settings . In other words just including the WSO2 product inside a pure FROM scratch Docker image will not work. Java requires various OS level utils and in turn they require a considerably laid out initial file system. Therefore, WSO2 parent images shouldbe Operating System images.
When it comes to selecting a parent operating system image for the WSO2 Docker image, consider the following criteria.
- Do you havespecific tools that are supported only on a certain distribution? e.g. monitoring and log collection agents, continuous auditing tools, configuration automation agents/tools
- Do you havesecurity concerns when it comes to the OS that favor a specific OS and a version with previous experience? Some OS images have more tools and utils that accompany the main Containerized process. Those additional processes potentially expose an attack surface through unknown (and sometimes known but not properly secured) vulnerabilities.
- Do you have organizational policies and restrictions that dictate use of only a specific OS and a version for any work to be done inside the organization? This can be part of a security audit based recommendation or more business oriented with enterprise support and partnerships involved.
- What is your most experienced expertise on? Is it Debian, RedHat, or Arch (or something else) based? Do your existing shell scripts support a flavor-agnostic deployment or are they dependent on a specific Bash version and/or a Linux flavor? Switching to a whole new OS image may put unnecessary pressure on your Ops (and Dev) cycles.
- Which OS images offer the lowest sizes possible within the business requirements? Would a minimal Alpine OS image cover all the scenarios in question with the same level of performance, security, and ops efficiency that a more full-fledged distribution like Debian or RedHat does?
WSO2 offers Dockerfiles and init scripts for Ubuntu, CentOS, and Alpine as Open Source artifacts. Furthermore, Docker images (built using the above Dockerfiles) are available on the WSO2 Docker Registry to be pulled directly.
Dockerfile Composition
When it comes to the Dockerfile which is the descriptor for the consequent image being built, there are various optimizations and best practices to follow for a cleaner, more debuggable, and more build-time efficient processes.
Copying the WSO2 product— WSO2 products are distributed as compressed zip files, downloadable from the WSO2 site or buildable through WSO2 Update Manager with a Support Subscription. Copying this pack to the Docker image would most probably be done as a conventional COPY instruction and then a subsequent RUN instruction would unzip the pack to a desired location.
However, this approach is a sub-optimal one when it comes to both the build cache and the image size. COPY instruction adds a layer close to the size of the zip file to the Docker image. The subsequent RUN instruction also adds another layer with similar or more size since it will be doing COW (Copy-On-Write) operations on contents of a previous layer. Furthermore, if you’re not careful, the copied zip file could also be packed into the final image along with the extracted product. For a WSO2 API Manager Docker image, this can add more than 1GB of size to the final Docker image.
What official WSO2 Dockerfiles have followed to overcome this limitation is a simple one. The WSO2 pack is extracted before it’s being copied to the Docker image, in the Dockerfile context location. The COPY instruction copies an extracted folder to the Docker image. This approach removes the need to add a specific RUN instruction to extract and delete the zip file. Furthermore, any changes that have to be done to a product pack (e.g. change the theme configurations for WSO2 API Manager Publisher UI) can be done outside of the Docker image build process, saving both the build time and the image size.
To add another small detail, when copying and configuring the WSO2 pack inside the Docker image, keep a note to do so in the same locations as a VM based deployment would do. For an example, if on your typical VM based WSO2 deployment, the product is running from /opt/wso2am-2.6.0 with /opt/wso2am acting as an easy access symbolic link, do the same in the Docker image as well. This will make the life much more easier for the Ops work that involves setting up tasks like monitoring and logging, and post-incident troubleshooting.
WSO2 products are also available as OS specific installers such as .deb or .rpm packages. In this case, they are installed to a specific location unique to the OS (e.g.
/usr/lib/WSO2).
Presence of the JDK— As stated earlier, WSO2 products need a JDK implementation to be run. The supported JDKs can be found at the documentation on compatibility. For Docker images, this can be a JDK copied from outside, or a JDK already present in the parent image.
Similar to the above description involving the WSO2 product, copying, extracting, and configuring the JDK could add undesirable size to the image. A similar solution could also be carried out for the JDK, however editing the JDK should be done with care not to violate the Oracle JDK.
A better approach would be to use an OpenJDK image as the parent image. There are various Linux flavors supported in the list of tags available and it’s a simple FROM instruction as opposed to the combination of extract and COPY or even worse, a combination of COPY, RUN, and ENV.
Labels— Docker introduced image Labels recently as a way to embed metadata into the image. Leveraging this feature generously is a good precaution to take in order to increase both the observability and the accountability of a system, even if those are non-goals at the start of a project.
Build Args— Docker build time arguments allow values to be passed to the Docker image that can change the build process based on those values. For an example, a single Dockerfile can build images for multiple WSO2 API Manager versions with a --build-arg specifying the version number at build time. This approach can save a lot of repetition and maintenance overhead for Dockerfiles that otherwise would have to be achieved through “clever” workarounds.
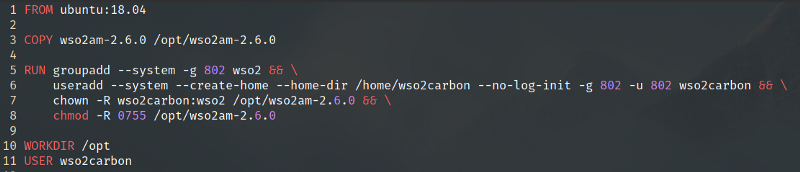
RUNInstructions— RUN instructions and the ordering of them contribute directly to the size of the final image and the readability of the Dockerfile. For an example consider the following simple Dockerfile.
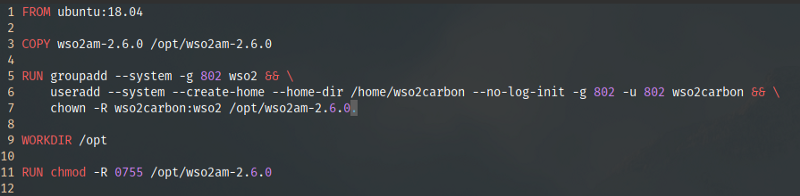
What this does is to copy the wso2am-2.6.0 folder to /opt/ (as we discussed above), create a Linux user and a group named wso2carbon:wso2, change ownership of the WSO2 product to the created user and group, and then change their Linux permissions to 0755 (user-rwx, group-r-x, world-r-x). The same can be written as the following where the WORKDIR instruction is moved after the chmod operation and merging the RUN instructions together.
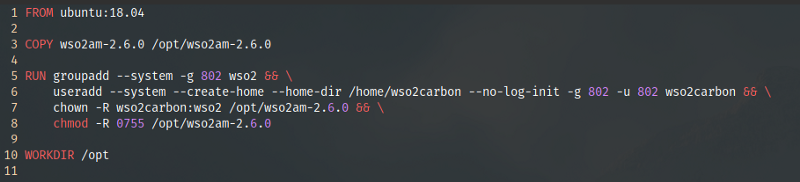
Now let’s compare the resulting images, wso2am:2.6.0.v1 and wso2am:2.6.0.v2.

As evident, the change in the ordering of the RUN instruction has resulted in an image size difference of 550MB. That is a huge difference in size for a simple chmod operation. Looking at the sizes of the separate layers, we can understand how this has come about.
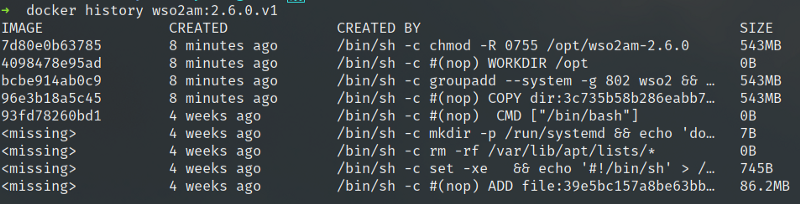
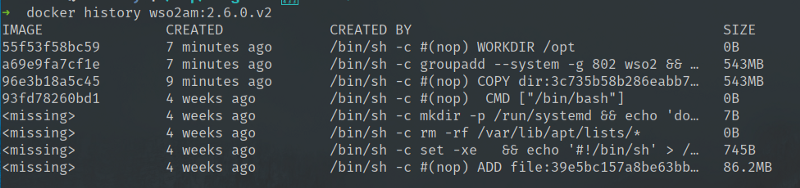
This is to do with the additional COW (Copy-On-Write) operations that chmod does on a separate layer. When we merge the sensible RUN instructions together, there is no need to do Copy-on-Write as the operations are happening in the same layer.
Least Privileged Users
Docker Containers are run using root user unless otherwise specified by a USER Dockerfile instruction. Although this is a root user on an isolated namespaced process (with other Kernel level jails in place), there have been proof of concepts that make use of vulnerabilities of the Kernel, applications, and tools involved to break out to the underlying host layer. If this exploit happens from within a Container running as root, then the Containerized exploited process will also have root privileges in the host.
Therefore, it’s advised as a best practice not to run Docker Containers with root user as the process owner. Like demonstrated above, creating a specific user (and group) with only access to the WSO2 product location and process is a suitable precaution.
Furthermore, when using the COPY instruction, the flag --chown can be used to set the ownership of the target location without having to add a separate RUN instruction to do so.
**EDIT:**It should be noted that the important detail to implement is the specific UID and the GID for the non-privileged user. A specific UID and a GID makes sure that no clashes or unanticipated side effects occurring between users and groups on the host and the Containers. A known value also makes sure that privileges can be restricted on the host machine for that specific UID.
Run-time Details
It’s most likely that there will be a thin bootstrap layer that acts as the main process of the Container. It will do some configurations, file manipulations, set environment variables, and finally will start the WSO2 Carbon server. It would be ideal to keep the list of bootstrap operations to a minimum to adhere to an agreed maximum Container startup time.
The script should ideally pass any runtime arguments set at the Container runtime to the wso2carbon.sh process that it would invoke at the end. This enables scenarios like having to open up a remote debug port to a specific Container, without having to modify the Docker image itself.
It’s important to understand the minor differences and the implementation nuances when it comes to the use of ENTRYPOINT and CMD instructions in the WSO2 Docker image. Mainly,
- Use
ENTRYPOINTinstruction to invoke the bootstrap script. TheCMDinstruction can be overridden and should be used for other purposes. - Use exec forms when specifying the
ENTRYPOINTinstruction. This will enable the use of later addedCMDvalues and overridden arguments. - The
CMDinstruction could be used in child images to enable a workflow where theENTRYPOINTin a parent image specifies the bootstrap script and theCMDinstructions in different child images can invoke the different functionalities in the WSO2 Carbon server, such as the OSGi console, remote debug ports, and setting various system properties. Based on this, there could be different (child) images to troubleshoot a scenario, enable or disable TLS1.2, or even going as far as to invoke different profiles of the same WSO2 server.
Init Process
One minor detail that is almost always kept out of discussions is the the process to be used as the parent process for Containers. Because of how Linux processes are supposed to manage child processes, Bash scripts do not make good init processes. Therefore, it’s always a good practice to invoke the bootstrap Bash scripts through a simple, light-weight, Container-friendly init system such as dumb_init or my_init. These will reap the child images gracefully and handle UNIX signals as they are supposed to be by a parent process.
Dynamically Loaded Configuration, Deployable Artifacts, and Logs
Configurations for WSO2 servers are mostly stored in XML files inside <CARBON_HOME>/repository/conf/ folder. Changes done to almost all of these files are not dynamically loaded. To make the changes take effect the JVM has to be restarted. In Container speak, this effectively means the death of the Container. Therefore, there is no possible user story where changes done to dynamically mounted configuration files can affect a running WSO2 server.
One useful exception to this is the logging configuration. Though the changes done to <CARBON_HOME>/repository/conf/log4j.properties file are also not dynamically loaded, WSO2 Carbon UI offers a configuration page that can be used to change the logging levels of all the loaded classes dynamically. Changing the values in this UI will take effect immediately, however those changes are in effect only until the JVM is shutdown.
On the contrary to the configuration files, the file based artifacts are dynamically loaded. These file based artifacts reside inside <CARBON_HOME>/repository/deployment/server in a single tenant deployment. Artifacts like Synapse configurations (proxy configurations, APIs, and other sequence definitions), event publishers and receivers, Jaggery applications, and web applications can be deleted and restored to take effect without having to restart the WSO2 server. Therefore, dynamically mounting these make the most sense rather than prebaking them into the image. Taking a prebake approach could force unnecessary build cycles to propagate minor deployment changes to live environments.
Another deployment aspect to be aware about are the instance local storages. These include the H2 database that contains the Local Registry, and the Solr indexes if present. Although these are specific to a single WSO2 server instance, the changes done in them during the runtime should be persisted across instance restarts. For Containers this means having to offload these artifacts to Container instance specific mounts that do not get deleted after the Container instance is stopped. Although losing these storages are not catastrophic to a deployment, rebuilding them (e.g. Solr indexes) could take time and result in unanticipated side effects. For an example, a missing Solr index of a WSO2 API Manager Publisher instance could result in a brief empty list of APIs in the UI.
Log files are generated by each instance separately. However, keeping these only in the ephemeral file system provided to the Container will create a troubleshooting nightmare where logs of the killed Containers are missing in action after the Container file systems are deleted. Ideally, logs should be pushed off to a centralized log aggregator (and analyzer). How to do this for systems like Splunk and ELK are well-tested well-documented scenarios. If such systems are not in place yet, logs can simply be mounted out to the host instance, that would probably sync them to a remote storage for archival.
Config Automation
Because of the flexibility of WSO2 servers to adapt to most use cases, the servers themselves contain a large list of configuration options. At the beginning of a deployment, these changes would most probably be small, including only the hostname, port offsets, and may be a few datasources. It’s tempting to do these changes only with the initial bootstrap scripts that involve tools like grep and sed. However the use of these tools quickly become overwhelming when the larger scope of configurations come into play.
Configuration Automation is almost always recommended as a tool for deployment management for WSO2. Apart from managing the large list of configurations and artifacts that WSO2 servers manage, a Configuration Automation system will also streamline the propagation of new fixes shipped by WSO2 through the WSO2 Update Manager (WUM).
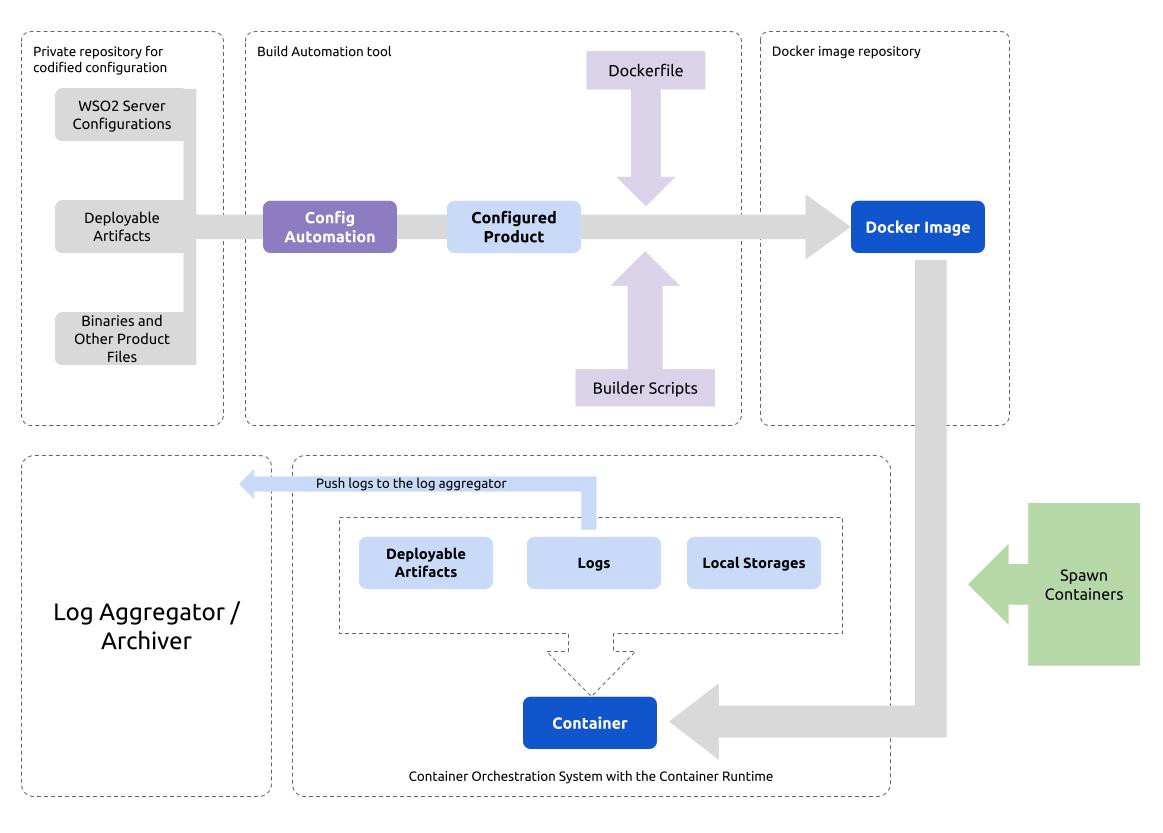
When it comes to Containerization, a Configuration Automation tool will be helpful in the image building process to prebake the required details in to the file system image. These details should include the server configuration, the binaries, the theme files, customizations, and the patches required. It can also include deployable artifacts, taking the approach the fully prebake end, however they should be in sync with the runtime deployable artifacts location for the new images to contain the latest artifacts (It should be noted that the better approach that would suit most use cases would be to use an approach where all except the deployable artifacts are prebaked into the image and have the deployable artifacts be mounted to the Containers during runtime). This process can be plugged into a build automation tool like Jenkins where image building based on changes done to the configuration can be automated (Continuous Integration) and new changes can be propagated to the live system through a combination of the Container Orchestration System (e.g. CoreOS Operator Pattern) and the build automation tool functionality to seamlessly spawn new Containers on top the newly built images (Continuous Delivery).
Official Configuration Automation artifacts for Puppet and Ansible for WSO2 products are available in WSO2 Github repositories. These are designed in a way that is suitable for most basic use cases, but at the same time they are easily adaptable to an increasingly complex but organizational (or even deployment) specific stories.
Generic Approach
Considering the above (somewhat long) list of options available, it’s easy to get lost in the details. A generic middle path approach would be to consider the 80% of the use cases and design your Docker image for that. Containers charge almost no cost in terms of compute power to kill and respawn however they incur costs in terms of management and operational complexity. Properly designed Containerization strategies should try to minimize this complexity and streamline the processes to be invisible during day-to-day operations.
Most use cases will strike the perfect balance between usability and Docker image size with Ubuntu base images. Ubuntu contains most tools required to troubleshoot development user scenarios. With smart Dockerfile composition, the size of the image can be taken down to manageable levels.
Other than the deployable artifacts inside <CARBON_HOME>/repository/deployment/server folder, the logs files inside <CARBON_HOME>/repository/logs folder, and the instance local databases inside <CARBON_HOME>/repository/data folder, all the other product items including the scripts, configuration, and the binaries can be prebaked into the image at build time. This should ideally be done with a Configuration Automation tool like Ansible or Puppet to make use of features like environment separation, templating, and codifiability of configuration options. They will additionally make sure no unwanted, ad-hoc changes are pushed to the live systems by accident or by the need of urgency.
For deployable artifacts, direct NFS volumes or indirect volumes mounted in the host instance can be used to both update the running system and to do deployment synchronization where needed (e.g. WSO2 API Manager Gateway, WSO2 Enterprise Integrator, WSO2 Identity Server). Extra steps should be taken in order to make sure that these volumes are backed up properly as they will mostly be containing mission critical data that if lost would not be easily recovered or regenerated.
As mentioned, going with best practices adopting something like dumb_init or my_init will be better for Container management. This will invoke a bootstrap script that does minimal setup operations like setting environment variables, and moving deployable artifacts to correct locations from mounted locations.
Logs should be pushed off to a centralized log aggregator. The mechanisms to do this does not drastically differ between development and production systems. Therefore, initial time invested in setting this process up will not be wasted later.
Build and Deployment Pipeline
As mentioned above, a build pipeline for Docker images that takes care of Continuous Integration and Continuous Delivery of the changes to live systems will force all other pieces to fall into place. It will require a repository of configurations that demands the use of a Configuration Automation tool. The build times will have to be managed. This demands proper design of the Dockerfile and the decisions on which parts of the runtime to be prebaked and which parts to be dynamically mounted, to be made early in the process. Change Review and Approval processes will come into affect once the configuration is codified. As a result of all these processes coming into perfect harmony, time to market will drastically reduce, utilizing the Container advantage to the maximum possible.
Conclusion
As evident from the above facts, the design of the Docker image will make its effect known to the top business decisions based on the operational effectiveness of the new technological stack chosen. Therefore, the minute decisions that have to be taken from how to change WSO2 server configuration to how to automatically propagate changes to the production system, have to be done so with all the details in hand.
The above guidelines and tips will help to go through the decision process with an informed mind. It’s not about sticking to only the vendor recommended Containerized approach, but knowing where and how to make compromises to the recommended flow in order to adapt it to suit organizational and technical requirements of the deployment. As long as the criteria within which the WSO2 Containerized deployment has to be operated are known and met, any approach that makes both the operational and business goals achievable and makes lives easier in the process is the best one.
Written on December 24, 2018 by chamila de alwis.
Originally published on Medium