
Harbour on a misty day
I’m getting back to writing after more than an year of a gap. A lot happened during this period, moved from one city to another, changed employers, but mostly, I think I switched my writing time for some PS4 time. At one point though, you come to accept that your best K/D is going to be 0.2 and you’re too old to get better. In any case, I managed to do a few rounds of bug fixing to my Kibana Prometheus Exporter, and learn a few things in an area I didn’t have that much of experience in, Big Data.
Introduction
Apache Nifi
One of the products I got to closely work with during the last year was Apache Nifi. Nifi is a data transformation tool, that boasts a strong visual interface. Data can be consumed from various types of sources, transformed with various tools, and then posted back to various types of sinks.
These transformations are defined as Flows, one of which would be a series of Processors. Processors are the building blocks in Nifi.
At it’s core, a Processor is a Java Class that implements a Processor Interface, with a onTrigger() method that implements what should happen to a Data Event that’s passing through the Processor. This could be a consuming function (such as reading from a Kafka topic, a remote HTTP endpoint, a JMS topic, or a vendor specific protocol), a transformation function (such as modifying attributes, changing formats, building a new message format from existing/computed values), or a publishing function (such as publishing to a Kafka or JMS topic, calling a remote HTTP endpoint). Various Flows can be grouped together into Flow Groups as well.
If you’re familiar with the ESB pattern in middleware, you may notice similarities between what Apache Nifi does and what a traditional ESB does. They both can glue disparate systems that speak different languages together, and does so in an extensible manner. In fact, if you’re familiar with something like WSO2 ESB, and the underlying Apache Synapse Engine you’ll notice that Processors in Nifi are almost a clone of Synapse Mediator design. It’s clear that the user stories these two areas cover, overlap a lot.
However, Nifi seems to focus more on data transformation rather than being a middleware messaging platform. It builds on Big Data concepts like Data Lineage from the ground up, and emphasises on factors like QoS, and scalability. Each Data Event (called a Flow File in Nifi) is tagged with metadata like origin and the transformations done on it, and is stored in persistent storage between Processor steps. This ensures both data lineage and durability for each Data Event.
Why CI/CD?
All this is good, but where do you need CI/CD in this, you ask?
Nifi user story involves one or more data engineers working together in the Nifi UI to build the Flow Groups. This results in a really good transformations, however, the next issue is to build a path to production for these transformation Flow Groups. At the moment, Nifi does not have any concept of packaging the transformations, so you can’t technically take a packaged set of transformations through a dev, test, staging, prod workflow. This is the CI/CD story I’m trying to address.
The solution Nifi puts forward is something called a Registry. A Registry is a component in Nifi which can be used as a wrapper around a Flow persistence method. This method could be something like a Git repository, a file system path, or an SQL database. The Nifi Registry introduces an abstraction layer on top of these persistence methods, so that irrespective of the underlying complexities, Nifi can interact with a stable API to perform reads and writes.
The Nifi Registry has the following concepts.
- Bucket - a Bucket is a container for a set of Flows. This can be used as a mapping for different concepts (an environment, a business unit, or even based on separate Nifi deployments since a Registry and a Nifi deployment are not coupled together)
- Flow - corresponds a Flow persisted using the Registry
- Version - each persisted Flow is versioned and can be referred to by a specific version.
A Bucket will have a number of Flows and a Flow will have a number of Versions.
We are going to use a Git repository as the Flow Persistence layer. This will make it easy to decouple the actual storage from Nifi and the Registry even more (and the specific deployment I used this pattern in was an OpenShift deployment managed by a team at the client side of things. Using the Git persistence in that case allowed me to avoid several different issues when it comes to sorting out storage in that environment, least complex of which were technical). It also gives us another layer of traceability where we’d be able to track down changes to a particular Flow in the Git commit history.
Nifi talks to the Registry through a REST API, so in terms of connectivity, all we have to do is to make sure there is a clear line of communication between Nifi and the Registry (clean up your NetPols if you’re in K8s).
For the sake of simplicity, I’m going to ignore user management features provided by the Registry, though that part of the product also brings in a set of features that will be essential in a production environment.
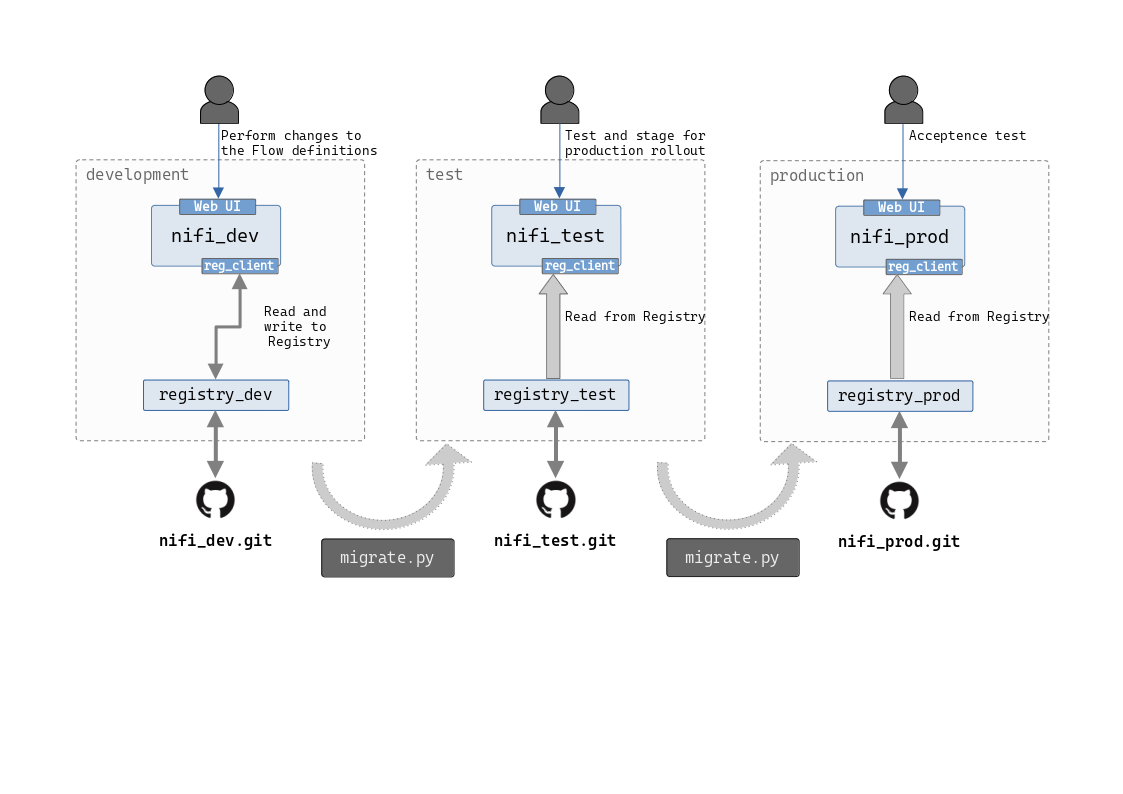
Git Persisted Nifi Registry
In our setup, we have the following three Nifi environments.
- development
- test/staging
- production
The Nifi Flow Groups will all be persisted in one Bucket in the Registry to keep things simple, and the Bucket name will be the same across the three environments too. This will require a Registry deployment per environment, however considering that Nifi Registry was first considered to be part of the core product, that pattern does not sound bad at all. Also, it makes sense to separate at least the prod and non-prod Registry instances, specially if certain compliance requirements demand that.
We will have to use a Git repository per Registry deployment. This is because of the fact that at the moment, there is no way to differentiate branches in the Git Flow Persistence provider configuration in the Registry.
With these components configured, we’ll use the Nifi and Registry APIs to transfer the changes done to the Flow definitions from one environment to the other, by using export and import functions. To do this, we’ll use a wrapper SDK Nipyapi.
Implementation
Configuring the Components
We first need to set up the Registry so that it’s working with a proper Git repository. For this blog post, I’m going to run the Nifi and the Registry instances locally, however, these details do not change if the deployment platform changes.
Git Repository
For the purposes of this demo, just a plain old Github repository for each environment repository would do. I’m going to be using the following.
- development -
https://github.com/chamilad/nifi-registry-dev.git - test -
https://github.com/chamilad/nifi-registry-test.git
Registry
First download Nifi Registry binary and extract it to two locations to match dev and test instances. If you’re running both of these on the same VM/system as I am, you’ll need to offset the ports in one instance, so open up configuration file conf/nifi-registry.properties in the test instance and change nifi.registry.web.http.port=18080 line to be nifi.registry.web.http.port=28080.
# web properties #
nifi.registry.web.war.directory=./lib
nifi.registry.web.http.host=
nifi.registry.web.http.port=18080 # change this value
nifi.registry.web.https.host=
By default, the Registry is configured to use the file system as the Flow persistence provider. We will change this so that the dev Registry points to the chamilad/nifi-registry-dev and test Registry points to chamilad/nifi-registry-test repositories.
We do this by modifying the configuration inside conf/providers.xml file. The XPath of the configuration we are looking for is //providers/flowPersistenceProvider[contains(class, "FileSystemFlowPersistenceProvider")].
default configuration
<flowPersistenceProvider>
<class>org.apache.nifi.registry.provider.flow.FileSystemFlowPersistenceProvider</class>
<property name="Flow Storage Directory">./flow_storage</property>
</flowPersistenceProvider>
Let’s comment this block out and add the following block, which points the persistence layer to the chamilad/nifi-registry-dev repository.
modified configuration
<flowPersistenceProvider>
<class>org.apache.nifi.registry.provider.flow.git.GitFlowPersistenceProvider</class>
<property name="Flow Storage Directory">./flow_storage</property>
<property name="Remote To Push">origin</property>
<property name="Remote Access User">chamilad</property>
<property name="Remote Access Password">mypersonalaccesstoken</property>
<property name="Remote Clone Repository">https://github.com/chamilad/nifi-registry-dev.git</property>
</flowPersistenceProvider>
Replace
mypersonalaccesstokenwith a GitHub Personal Access Token you’ve generated for this task. This token should be able to read from and push to the repository you have chosen as the backend.
Let’s do the same for the test Registry instance and point it towards chamilad/nifi-registry-test repository.
<flowPersistenceProvider>
<class>org.apache.nifi.registry.provider.flow.git.GitFlowPersistenceProvider</class>
<property name="Flow Storage Directory">./flow_storage</property>
<property name="Remote To Push">origin</property>
<property name="Remote Access User">chamilad</property>
<property name="Remote Access Password">mypersonalaccesstoken</property>
<property name="Remote Clone Repository">https://github.com/chamilad/nifi-registry-test.git</property>
</flowPersistenceProvider>
We are now ready to start the Registry instances properly. Run bin/nifi-registry.sh start and tail -100f ../logs/nifi-registry-app.log to monitor startup process. After the Registry starts up, visit the address http://localhost:18080/nifi-registry on the browser and you’ll be presented with something similar to the below.
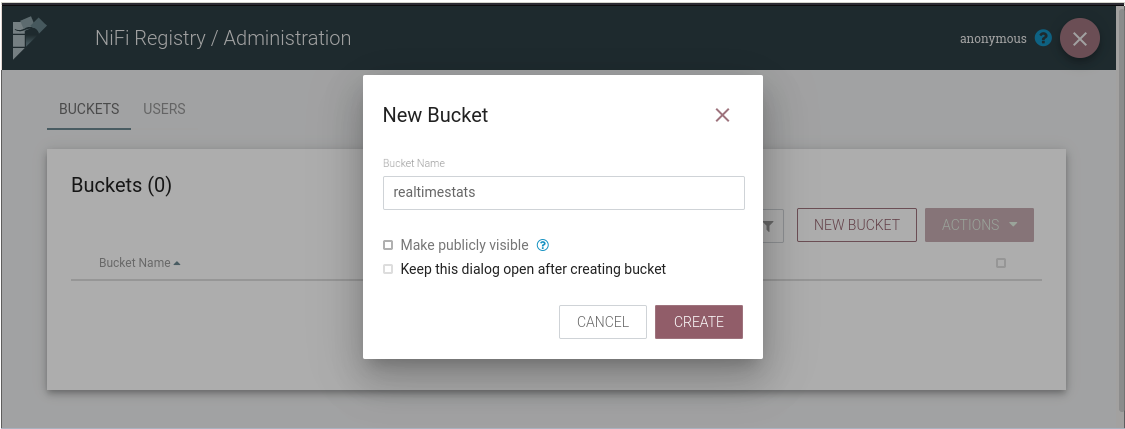
Let’s complete the Registry set up by creating a Registry Bucket to act as a Container for the Flows that we’ll be pushing to the Registry. Click on the Spanner icon on the top right corner (or visit the administration UI at http://localhost:18080/nifi-registry/#/administration) and select New Bucket. Let’s use realtimestats as the Bucket name.
Do the same in the test Registry instance.
If you visit the Git repository to see if anything has changed, you’d be a bit disappointed. A Registry Bucket is a Git directory, and as you may know now, there is no such thing as an empty Git directory. We will not see anything change in the Git repository until we start pushing Flow definitions to the Registry.
Nifi
Download the Nifi binary and extract two instances out of it. Do the same port off set for the test instance (conf/nifi.properties).
nifi.web.https.host=127.0.0.1
nifi.web.https.port=8444 # offset this by one
nifi.web.https.network.interface.default=
Start the Nifi instance by running bin/nifi.sh start and tail -100f logs/nifi-app.log to see if the JVM Container starts up without an issue. After this, visit Nifi UI at https://localhost:8443/nifi (and https://localhost:8444/nifi for test).
For the recent versions, Nifi generates a user and a password when it starts the first time. If you’re greeted with a login screen, go back to the
tailoutput and find the credentials there. And you’ll have to log into the two Nifi instances from two different browser sessions (one in a Private Window, or different Firefox Containers).
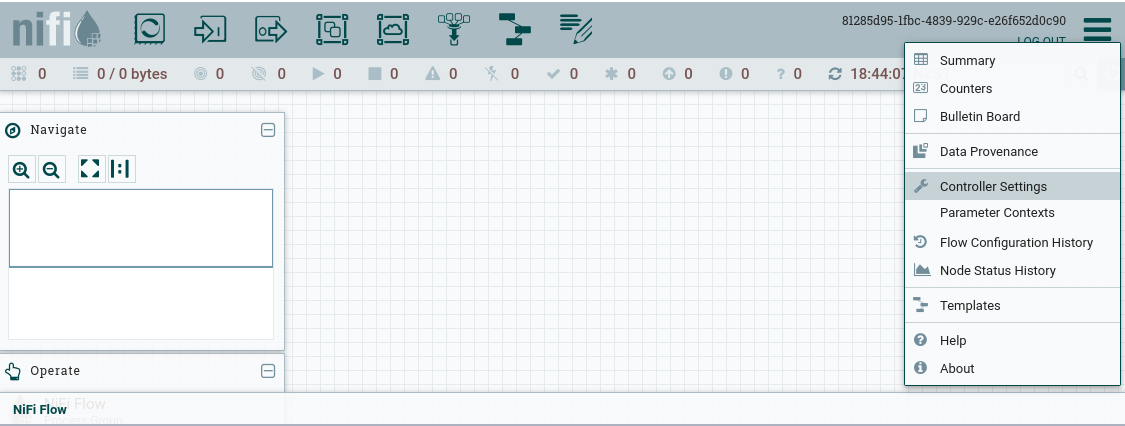
By default, Nifi does not point to any Registry component. We change this by adding a Registry Client so that Nifi knows that Flow definitions will be version controlled and where to talk to when doing so. To do this, go to Settings menu (three lines on the top right corner) -> Controller Settings -> Registry Clients -> New Client (plus sign icon)
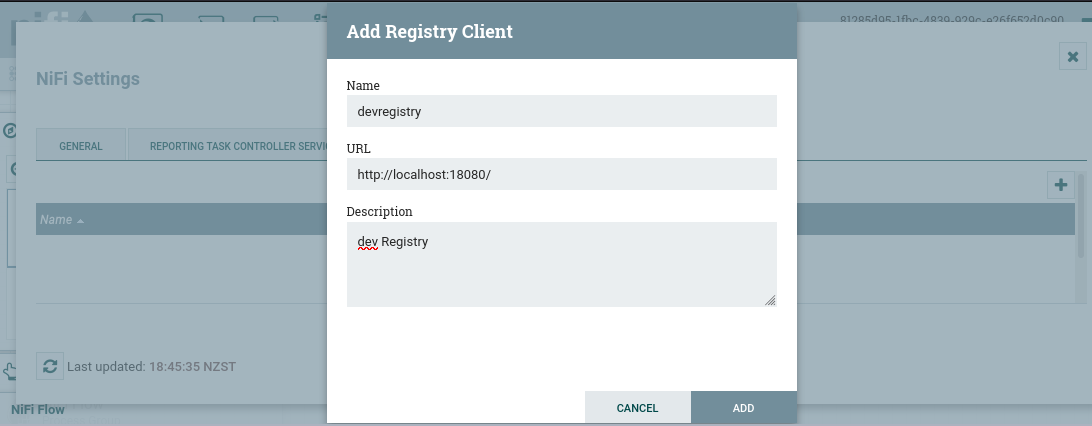
The Registry URL should only be the
hostand theport, not the/nifi-registrypath.
Do the same in the test Nifi instance and point it to the test Registry.
We have now set up the plumbing necessary to integrate Nifi and the Nifi Registry setup. I have also added a sample Process Group with a single Flow that generates a Flow File (data event) every 5 seconds and output to stdout.
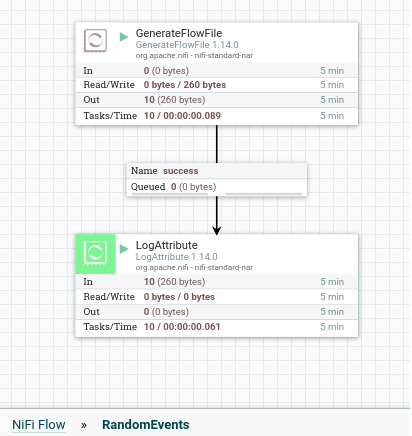
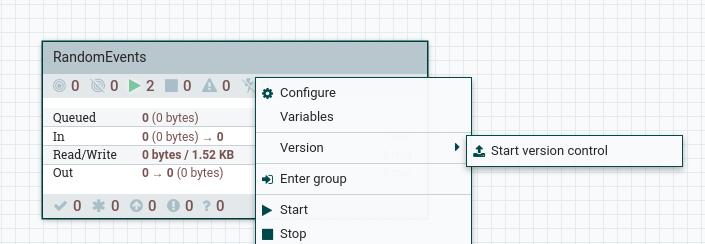
Since we have integrated the Registry to Nifi, we can directly commit this Flow to Registry. To do that, go to the top level UI, right click on the Process Group, Version -> Start Version Control. In the resulting dialog box, add the necessary details.
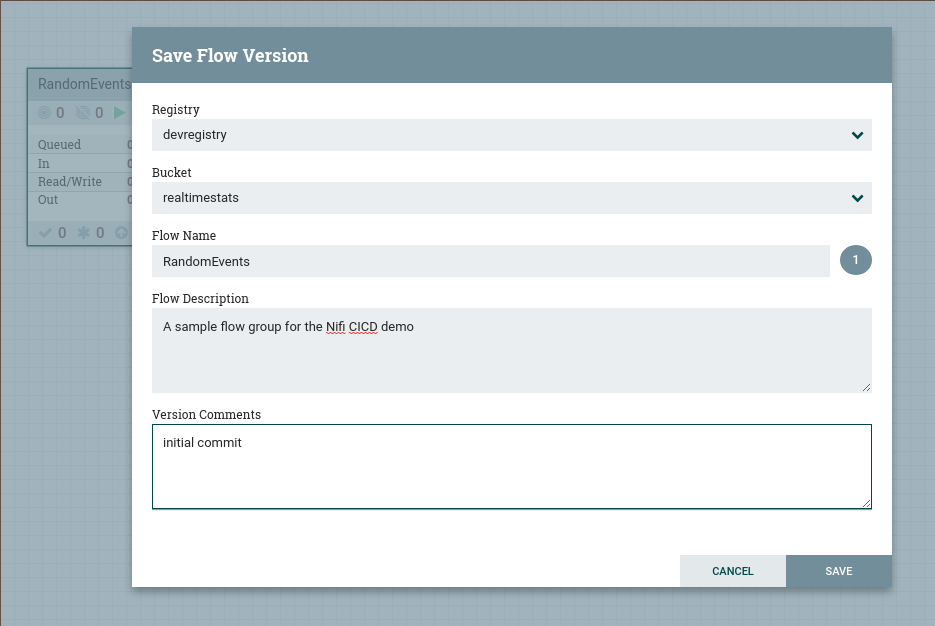
Visit the dev Registry UI and you will see the Flow Group RandomEvents that we just added to version control being displayed under the realtimestats Bucket.
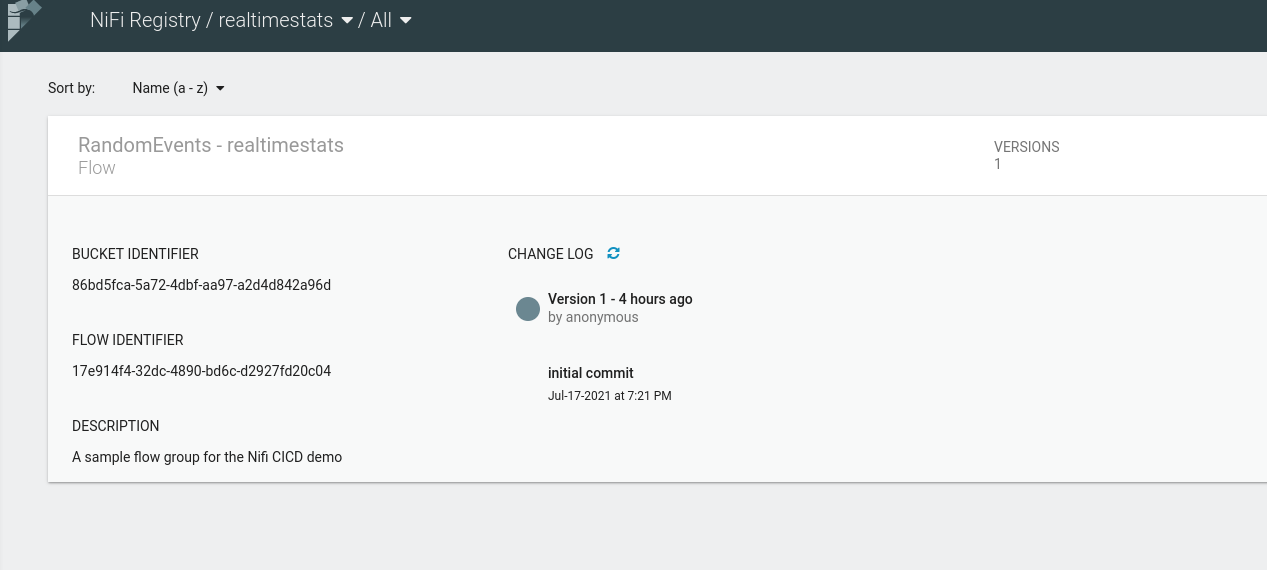
If you visit the dev Git repository after this, you’ll see the directory named realtimestats which is the Registry Bucket we made earlier. And inside that directory there will be two files, one corresponding to the Flow Group named RandomEvents.snapshot and another file which is the descriptor for the Bucket, named bucket.yml. This is our starting point when automating the CI/CD flow for the Flow definitions.
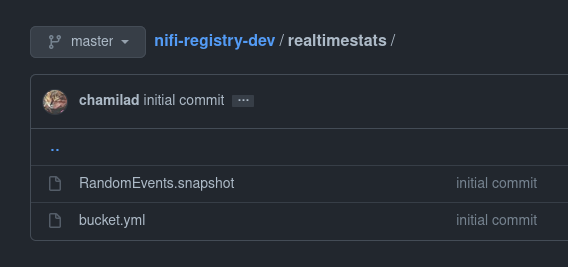
So far, we set up the basic components of a typical Nifi deployment with a Registry primed for CI/CD. You can break off from this point, and build your way of doing things, since the Registry just opens up a number of possibilities. You can manually perform export and import actions and call it a day. However, with a little bit of scripting, we can automate a bunch of these actions. Let’s address that part in the next post.