
The morning shadow on the lower mountaineous plain beside Adam's Peak, Sri Lanka
This is part of a series of short articles on setting up an ELK deployment on K8s.
- ElasticSearch on K8s: 01 — Basic Design
- ElasticSearch on K8s: 02 — Log Collection with Filebeat
- ElasticSearch on K8s: 03 - Log Enrichment with Logstash
- ElasticSearch on K8s: 04 - Log Storage and Search with ElasticSearch
- ElasticSearch on K8s: 05 - Visualization and Production Readying
- ElasticSearch Index Management
- Authentication and Authorization for ElasticSearch: 01 - A Blueprint for Multi-tenant SSO
- Authentication and Authorization for ElasticSearch: 02 - Basic SSO with Role Assignment
- Authentication and Authorization for ElasticSearch: 03 - Multi-Tenancy with KeyCloak and Kibana
Storage and Indexing
Now that the logs are translated into a meaningful set of data, it’s time to store and index them for querying. ElasticSearch is the tool of choice, the main attraction of the stack to be honest. It’s an efficient useful tool to store and index unstructured data. How ElasticSearch’s design (which is something that was done in a time when Docker was not even invented yet) is matched to K8s is an interesting story of itself.
Shards and Indices
In its core, ElasticSearch is only a collection of carefully managed Apache Lucene instances. They store and index the given unstructured data. Each of these Lucene instances is called a Shard in ElasticSearch terms. Typically two of these Shards (one called a primary shard, the other the backup shard) is called an Index. ElasticSearch makes sure to never schedule both of the Shards of the Index in the same ElasticSearch node, to avoid data loss.
I said “typically” because the number of shards per index could vary depending on user preferences. There was a time when 5 shards, 1 primary and 4 backups was suggested as a sensible default. Number of shards per index is best decided early in the design and deployment, as changing this later, when there are a large number of indices to change, would be a hassle.
Other than the number of Shards per index, ElasticSearch requires very little in terms of configuration to startup. However, just one ElasticSearch instance is not considered a healthy cluster, and given that the resource usage of the Shards go up proportionately to the number of requests and the data stored, it’s a good idea to scale out from the get go. In the previous article, it was discussed how Logstash could send logs from different sources on different dates to separate indices in ElasticSearch. For a small K8s cluster with two Namespaces, this pattern would create at least four new Shards in the ElasticSearch cluster. This can easily get out of control and result in resources being wasted on idle maintenance cycles for the running Shards. Furthermore, scaling out an existing ElasticSearch cluster could result in a considerable downtime (especially if the ElasticSearch cluster already has a high number of running Shards), since Shards may have to be rebalanced among the new instances of the cluster. So it is important to figure out the cluster requirements before the deployment.
It’s important to manage the active number of indices in an ElasticSearch cluster for optimal resource usage. With a high level of granularization between indices, this maintenance will have to be automated. Let’s discuss the use of Index Lifecycle Management Policies to keep an ElasticSearch cluster clean.
Scheduling and Networking
For our sample problem, a 2-node ElasticSearch cluster is enough, although better fault tolerance is achieved with odd numbered clusters, as odd numbers reduce the possibility of split-brain situations during most faulty scenarios. However, for the scope of this article, the configuration that would work for a 2-node cluster will also work for a 3-node cluster.
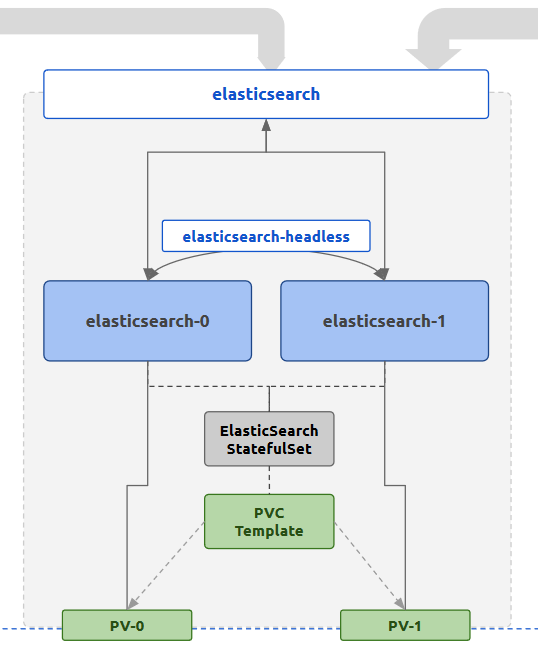
The K8s controller used for the ElasticSearch deployment is a StatefulSet. This is because of the persistence and network consistency that the log persistence tool requires. StatefulSets will schedule Pods in a manner that makes sure in case of Pod downtimes the same resources will be allocated to the newly created Pods during healing. These include any persistent volumes attached to the Pods in addition to consistent networking through the use of Headless Services where each Pod will have a standard consistent name to be reached. Each Pod is also started in a sequential manner where for a replica count of 3, the start sequence will be pod-0 , pod-1 , pod-2 . Each subsequent Pod will wait until the previous Pod becomes live and running. Together, these features provide a sane way of initializing a cluster where node membership is managed by well-known addresses rather than having to manage the dynamic nature of Pods in K8s.
In the StatefulSet, we are also going to define a PersistentVolumeClaimTemplate which generates a PersistentVolumeClaim for each Pod scheduled by the StatefulSet. The allocated PersistentVolume will be mounted to the location which ElasticSearch considers as the data directory, where all data is stored. This is because data should survive beyond Pod lifecycles, or even StatefulSet lifecycles.
In terms of networking, this setup use two K8s Services for ElasticSearch Pods. One is a typical ClusterIP Service named elasticsearch that exposes the ElasticSearch HTTP port, which by default is 9200. This can be used by outside processes (ex: Logstash, Kibana) to reach the ElasticSearch Pods in a load balanced manner. The IPs resolved for each call to the Service name could be the either of the Pod IP addresses.
The other Service is a Headless Service, where the Endpoint objects are created based on Selectors that match the ElasticSearch Pod labels. This is used by the StatefulSet to provide stable network IDs to the Pods through the Service name. For an example, for the sample setup, with a Headless Service named elasticsearch-headless in the default namespace, the two Pods generated by the StatefulSet elasticsearch will be reachable through the FQDNs elasticsearch-0.elasticsearch-headless.default.svc.cluster.local and elasticsearch-1.elasticsearch-headless.default.svc.cluster.local. These names can be used for the ElasticSearch configuration to bootstrap the cluster membership. The Headless Service attached to the StatefulSet will expose the clustering port of 9300 in addition to the HTTP port 9200 .
Bootstrap and Master Election Process
ElasticSearch nodes can play different roles in a cluster depending on the configuration. These roles include,
- data
- ingest
- master
In the sample setup we are discussing, both nodes are playing all the above roles. However, for a given cluster, there can be only one master node and all others nodes that hope to become one will have to be master eligible.
When an ElasticSearch cluster is first booted up, two tasks have to complete for a master node to be elected.
- cluster bootstrap (one time task that executes the first time the cluster nodes start up), where the first round of master eligible nodes (whose votes will be used for master election) are explicitly looked for
- discovery of master eligible nodes in the cluster, typically through a load balancing A record resolution
For a K8s setup, the Headless Service features that were described will help to complete both of these tasks.
- In the K8s ElasticSearch setup we are considering, both Pods will be live (determined by the StatefulSet, as opposed to one Pod being on standby until a single node goes down) so both Pods can be used as initial master eligible nodes. Since Headless Services provide consistent naming for both of the Pods, the names
elasticsearch-0andelasticsearch-1can be used for the related settingcluster.initial_master_nodes. The cluster when starting up for the first time, will consider the votes of both of these Pods and proceed with the master election. - When another master election comes (ex: cluster restart, master going offline), there has to be a method to discover newly joined Pods which are master eligible. In this case, any new Pods created as a result of scaling out will have to be discovered in order for election process to proceed. This can be done through the use of the Headless Service name, which when resolved will return all the Pod addresses (in contrast to a typical ClusterIP Service which will return only the Cluster IP address when resolved). Therefore, for the related setting
discovery.seed_hosts, the Headless Service nameelasticsearch-headlesscan be provided.
Since these names are known before the Pods are actually spawned, including them in a ConfigMap and making ElasticSearch Pods use that configuration is possible. This would not have been the case if a Deployment and a typical Service were used in place of the StatefulSet and the Headless Service.
The configuration for elasticsearch.yml could look like the following.
# bind to all IP addressses
network.host: 0.0.0.0
# production check
bootstrap.memory_lock: false
# discovery method for master elections
discovery.seed_hosts:
- elasticsearch-headless
cluster.name: elasticsearch
node.master: true
node.data: true
node.ingest: true
# master eligible endpoints for initial bootstrap process
cluster.initial_master_nodes:
- elasticsearch-0
- elasticsearch-1
With the successful and healthy GREEN ElasticSearch cluster, the data pushed from Logstash will correctly be stored and indexed. Now these can be queried for all kinds of purposes, through either the ElasticSearch REST API or the visualization tool, Kibana which will be discussed in the next article.